The Pattern You Know Isn't the Interview You're In
Most mid-level backend engineers recognize the minimum window substring problem on sight. Sliding window, two pointers, a frequency map: the pattern clicks in under a minute. That familiarity is also where the hidden point bleed begins.
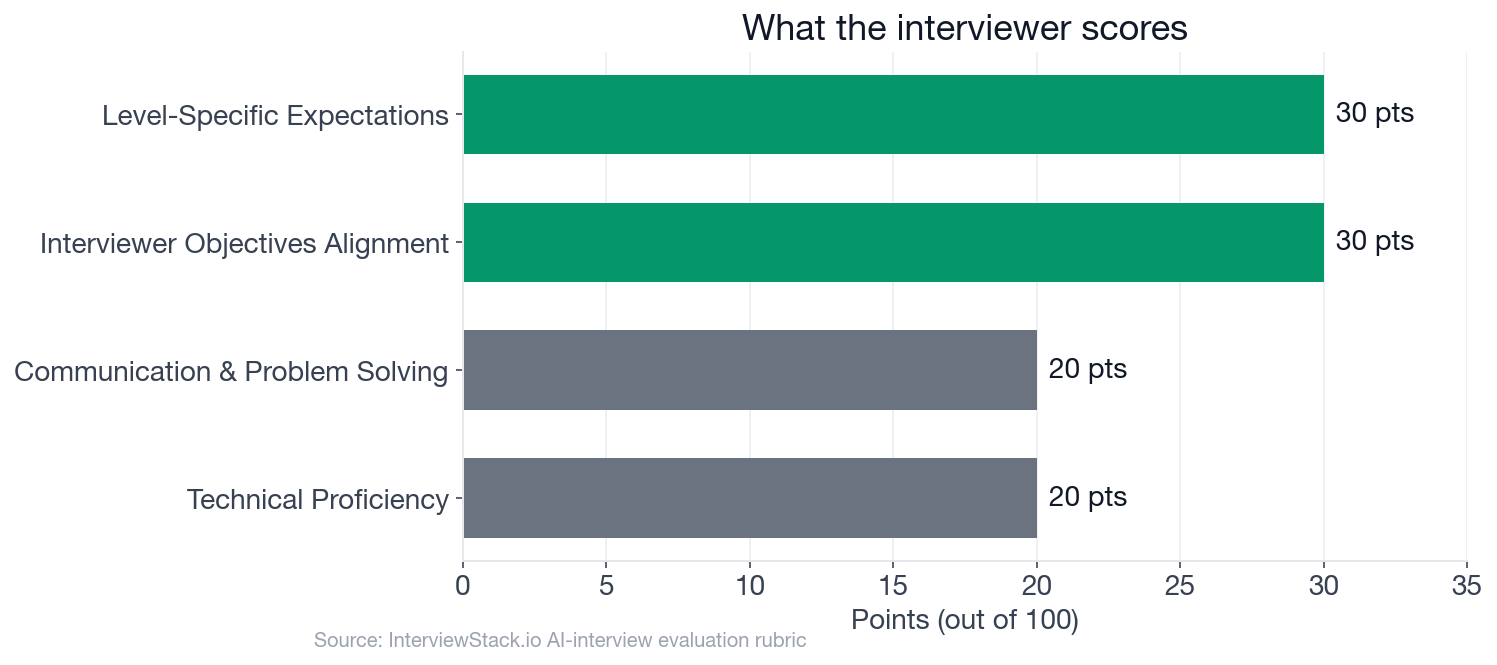
This is a 30-minute interview scored across four rubric dimensions. Interviewer Objectives Alignment (30 points) and Level-Specific Expectations (30 points) together account for 60% of the total. Neither dimension rewards pattern recognition. They reward the candidate who asks the right questions before writing a line of code, adapts the algorithm when the problem mutates mid-interview, and reasons aloud about trade-offs a production log-processing service actually cares about. The sliding window is table stakes. The 60 points around it are where mid-level candidates diverge.
Key Findings
- The rubric totals 100 points across 4 dimensions: Interviewer Objectives Alignment (30 pts), Level-Specific Expectations (30 pts), Technical Proficiency (20 pts), and Communication and Problem Solving (20 pts).
- 60 of 100 points depend on objectives alignment and level-specific expectations, not algorithm correctness alone.
- The 30-minute interview runs across 4 phases: problem framing (0-6 min), algorithm design (6-16 min), implementation quality (16-25 min), and testing and robustness (25-30 min).
- Mid-level candidates must arrive at a working O(n + m) sliding window without heavy prompting, and must distinguish counted satisfied frequencies from unique character requirements.
- The rubric requires at least 2 meaningful clarifying questions before implementation, targeting case sensitivity, character set, and empty-input behavior.
- Level-specific expectations include comparing fixed-size array versus hash map for frequency tracking, and raising at least one Unicode or encoding concern when prompted.
The Backend Developer Array and String Manipulation Interview Question
Here is how this question appears in a mid-level backend engineering interview at a leading tech company.
The interview question
You are working on a backend service that scans application logs for repeated error signatures. Each log line is treated as a string, and the service needs to find the shortest contiguous snippet of a log line that contains all characters from a given error signature string.
Function signature: minWindow(logLine: string, signature: string) -> stringExamples: logLine = "ADOBECODEBANC", signature = "ABC" -> "BANC" logLine = "a", signature = "aa" -> ""
Constraints:
- 0 <= logLine.length <= 200000
- 0 <= signature.length <= 10000
- The service may process many requests, so both latency and memory usage matter.
How would you implement the function above for our log-processing service?
The interviewer is evaluating fluency with core patterns, production-relevant judgment (encoding, memory, latency), and the ability to clarify ambiguous requirements before committing to a design. The log-processing framing is deliberate: this is not a competitive-programming puzzle, it is a service endpoint that must be fast, correct, and maintainable under real input variation.
How a Strong Candidate Handles the Follow-Up Turns
The walkthrough below covers 4 of the 6 follow-up prompts in the blueprint: the ones that carry the most scoring weight and reveal the sharpest gaps between prepared and underprepared engineers. The candidate in the mistake boxes is "Priya," a composite of common responses from engineers who know the pattern but have not drilled the adaptations.
Turn 1: Clarify First
Interviewer: "What questions would you ask me before committing to an implementation?"
Turn 2: Case-Insensitive, Original Substring
Interviewer: "How would your approach change if character matching is case-insensitive, but the service must return the original substring from the input?"
Turn 3: Fixed Array vs Hash Map
Interviewer: "How would you justify your choice between a fixed-size array and a hash map for frequency tracking?"
Turn 4: Timing Out at Scale
Interviewer: "Suppose this endpoint starts timing out on very large inputs. What would you profile or optimize first?"
Spotting Mistakes on Paper Is Only Half the Work
You can see exactly where Priya lost points in each turn above. That part is easy: the scoring logic is visible and the correct approach is spelled out. The hard part is producing those stronger moves in the actual interview, when you're 12 minutes in, still holding two pointer states in your head, and the interviewer pivots to a variant you didn't specifically drill.
That gap between review comprehension and live performance only closes through reps under realistic pressure. The Backend Developer Array and String Manipulation AI mock interview runs you through the full 30-minute session with an AI interviewer that tracks the rubric dimensions above in real time. The follow-ups arrive based on your actual answers, not a fixed script, which is the condition walkthroughs cannot replicate. If you want targeted drilling before the full session, the Backend Developer question bank covers array and string manipulation questions by difficulty and pattern. You can also browse current Backend Developer openings to see which specific skills companies are currently emphasizing in their postings.
The Complete 30-Minute Blueprint
Below is the full interview blueprint across all 4 phases: what a strong candidate hits, minute by minute, and exactly what the AI mock interview tracks you against in real time.
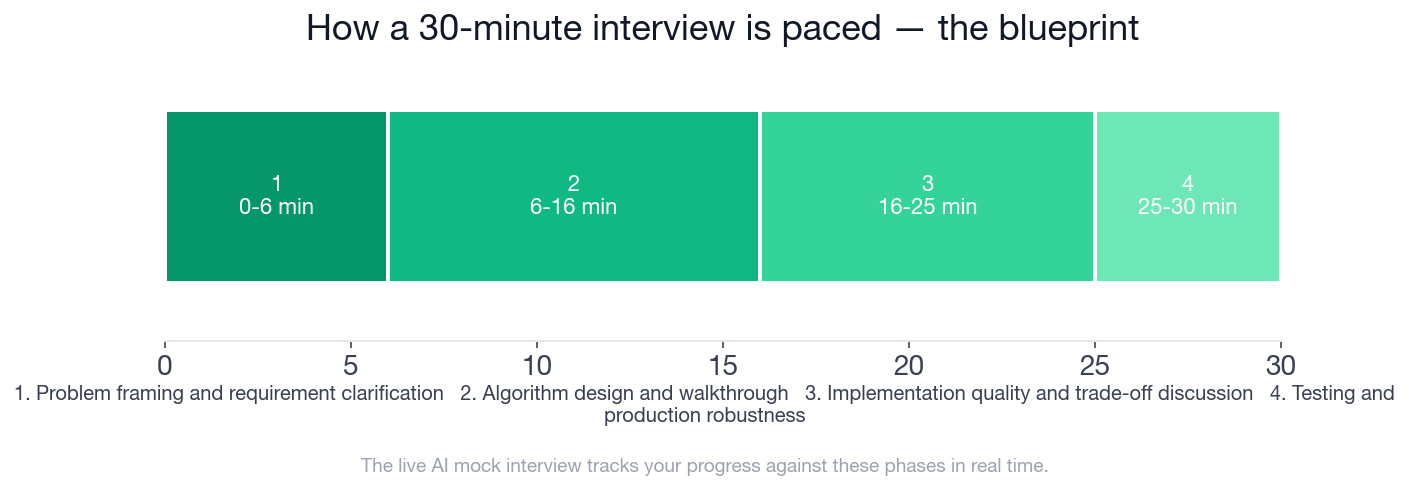
The 30-minute timeline above maps each phase to its window. Below, the scoring weights chart shows how the four rubric dimensions split the 100 available points.
- ✓Restates the task as finding the minimum-length contiguous substring containing all required characters with multiplicity
- ✓Asks at least 2 meaningful clarifying questions such as case sensitivity, character set assumptions, or expected behavior for empty signature
- ✓Rejects naive exhaustive substring generation as too slow for input size
- ✓Proposes left/right pointer expansion and contraction
- ✓Defines frequency tracking for required characters and current window
- ✓Explains a validity condition such as matched required counts or satisfied unique requirements
- ✓Walks through at least one sample and correctly describes when to record/update the best window
- ✓Identifies how repeated characters in the signature affect the counting logic
- ✓Produces coherent code or close pseudocode with correct pointer movement and updates
- ✓Handles edge cases: empty logLine, empty signature, signature longer than logLine, and no valid window
- ✓States expected complexity clearly, ideally O(n + m) time and O(k) space
- ✓Can compare fixed-size array versus hash map based on assumed character set and implementation language
- ✓Mentions substring copy cost or equivalent language-specific behavior if relevant
- ✓Suggests targeted tests for duplicates, ties, no-solution, full-string answer, and single-character inputs
- ✓Raises at least one Unicode or normalization concern when prompted
- ✓Offers a sensible optimization or profiling direction for latency issues rather than premature micro-optimization
FAQ
Q. What does a backend developer array and string manipulation interview cover?
The interview covers sliding window, two pointers, frequency hashing, and in-place versus extra-space trade-offs. For mid-level candidates, the rubric also probes production-relevant reasoning: Unicode handling, character-encoding assumptions, memory behavior, and test strategy. The 30-minute session runs across 4 phases: problem framing (0-6 min), algorithm design (6-16 min), implementation quality (16-25 min), and testing and robustness (25-30 min).
Q. How is a backend developer array interview scored?
The rubric totals 100 points across 4 dimensions: Interviewer Objectives Alignment (30 pts), Level-Specific Expectations (30 pts), Technical Proficiency (20 pts), and Communication and Problem Solving (20 pts). Objectives and level expectations together account for 60% of the score, so a correct solution that skips clarifying questions or production reasoning can still land in the 50-60 range.
Q. What is the minimum window substring problem in a backend interview context?
The classic minimum window substring problem is reframed as a log-processing service: given a log line string and an error signature string, find the shortest contiguous snippet of the log line that contains all characters from the signature. The backend framing adds constraints around latency, memory usage, and Unicode correctness that a pure algorithmic answer will not address.
Q. What mistakes do mid-level backend engineers make on array and string interview questions?
The most common mistakes are: jumping to implementation before asking clarifying questions (costs points in Objectives Alignment), failing to handle repeated characters in the signature correctly, conflating counted satisfied frequencies with unique character requirements, ignoring Unicode or encoding concerns when asked, and describing an algorithm without discussing data structure trade-offs like fixed-size array versus hash map.
Q. How should a mid-level backend developer prepare for array and string manipulation interviews?
Practice the core patterns (sliding window, two pointers, frequency hashing) until implementation is fluent, then shift to the adaptations: case-insensitive variants, Unicode constraints, large-input performance. The rubric weights Level-Specific Expectations at 30 points, so production judgment about trade-offs matters as much as a correct algorithm.
Q. What does the AI mock interview track during a backend developer array interview?
The AI mock interview tracks you against the 4-phase blueprint in real time: whether you clarified requirements before coding, whether your algorithm design handled repeated characters in the signature, whether your implementation covers edge cases like empty inputs and no-valid-window, and whether you raised encoding or Unicode concerns in the robustness phase.
The 30-Minute Standard
Knowing the sliding window is the price of entry. The engineers who score above 80 in this interview are the ones who treated the first 6 minutes as seriously as the implementation phase, connected their clarifying questions to their data structure choices, and arrived at the robustness discussion with something concrete to say about encoding and test coverage. That combination comes from deliberate practice on the full session, not from reading walkthroughs or reviewing solutions. The pattern is easy; the 30 minutes is not.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.