The Framework Layer Is Expected, Not Rewarded
If you ask hiring managers what separates a $200K+ Machine Learning Engineer from a $185K one, the honest answer rarely involves PyTorch vs. TensorFlow. It involves what happens beyond the framework: whether someone can run distributed training at scale, write production-grade C++ inference code, or understand why a model that passes offline eval degrades in production. The job boards are starting to price that gap explicitly.
Across 4,960 active Machine Learning Engineer postings on the InterviewStack.io job board as of June 2026, the US salary data tells a counterintuitive story. Python (66.6%), second only to Machine Learning (70.4%) among this role's required skills, carries a median US base of $189,300, which is $3,700 below the role's own $193,000 baseline. TensorFlow sits at $187,500. MLOps, which one in four postings explicitly requires, posts at $189,300. scikit-learn falls to $173,200. The skills that 25-65% of hiring managers list as expected are not the skills that move compensation.
What does move it: JAX (Google's high-performance numerical computing library used extensively in ML research) at $223,000 median, C++ at $209,700, the Transformers library at $202,500, and Distributed Systems at $200,500. C++, Transformers, and Distributed Systems each appear in 7–9% of all postings; JAX is more concentrated in research-lab roles and does not reach the 5% threshold in the full posting population. Across this tier, the salary gap above the standard framework layer runs from $7,500 to $30,000.
Key Findings
- 4,960 active Machine Learning Engineer postings analyzed on the InterviewStack.io job board as of June 2026 (4,954 distinct).
- Two table-stakes skills: Machine Learning (70.4%) and Python (66.6%) appear in more than two-thirds of all postings.
- LLMs (37.1%) and Generative AI (24.7%) are now common-tier: expected by roughly one in three hiring managers, no longer a differentiator.
- Median US base salary is $193,000 (n=1,272 postings with US salary data); equity and bonuses are not included.
- Python pays below the baseline at $189,300 median (US); TensorFlow posts at $187,500 and scikit-learn at $173,200.
- Systems-depth skills command the biggest premiums: JAX ($223K, +$30K, n=92), C++ ($209.7K, +$16.7K, n=138), Transformers ($202.5K, +$9.5K, n=121), Distributed Systems ($200.5K, +$7.5K, n=154).
- Entry-level is thin: only 4.7% of postings are entry-level (232 of 4,960); mid-level dominates at 54.4%.
- The US accounts for 44.6% of postings (2,212), a larger share than most other tech roles. Onsite leads at 54.6%.
Data note: The role classifier uses keyword-based matching. Review of the title sample suggests approximately 10–15% of postings may come from adjacent "learning"-keyword roles (L&D specialists, training consultants, or academic research postings) rather than product-building ML engineers. Headline ML skill frequencies are therefore slightly conservative; the salary and seniority data reflect the core MLE segment.
Which Skills Actually Pay Over $193K?
Salary figures in this section cover US postings only, where wage-transparency laws produce consistent disclosure, and represent base salary only: equity, RSUs, bonuses, and sign-on are not disclosed in postings, so total compensation at top-tier employers runs meaningfully higher, particularly in tech and finance.
The overall US median for Machine Learning Engineer roles is $193,000 (n=1,272).
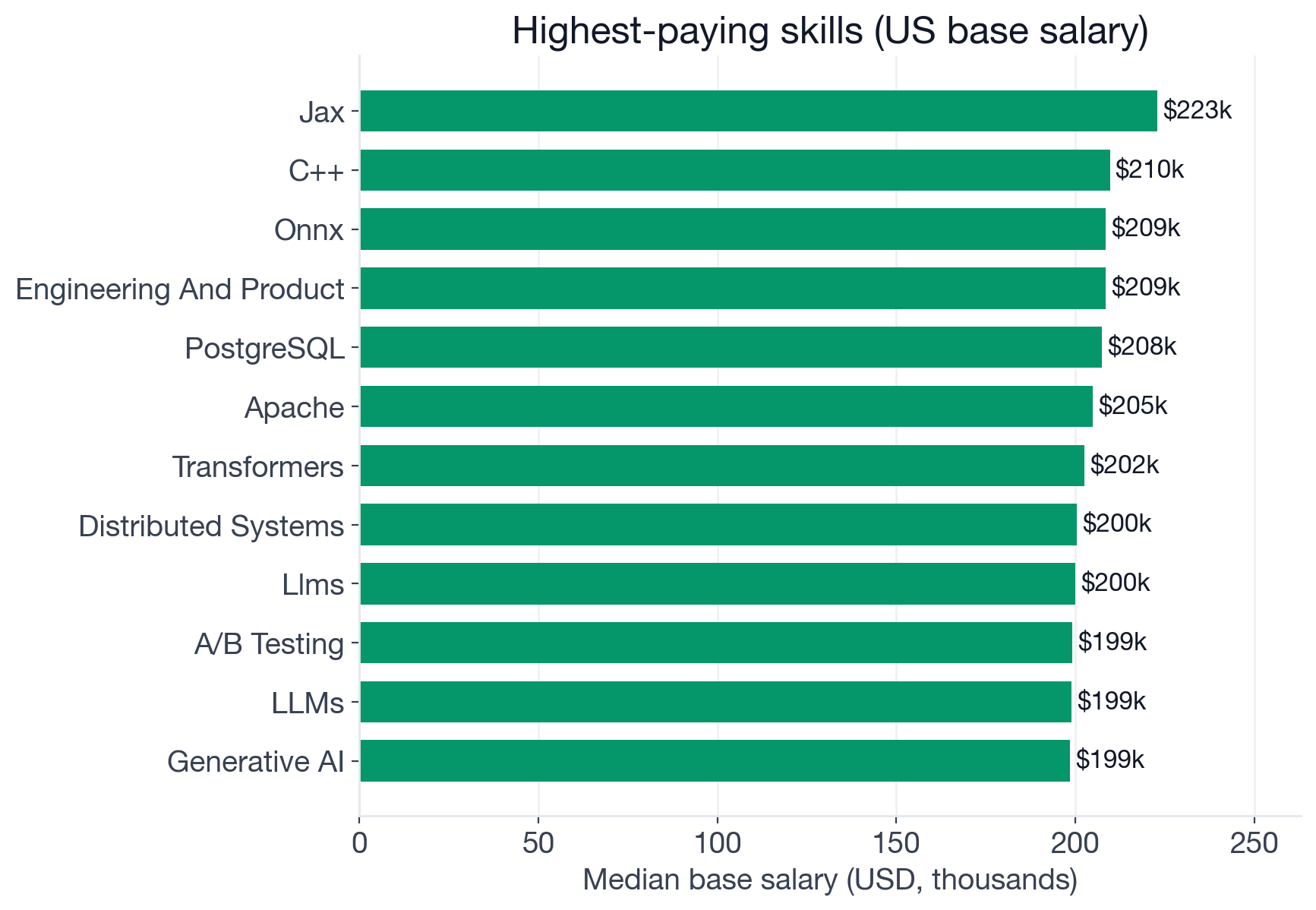
Median US base salary (USD) for Machine Learning Engineer postings that mention each skill. Restricted to skills with at least 25 US salary data points.
The salary picture divides into three groups.
The research and systems layer (+$7K to +$30K above baseline):
The largest premiums attach to skills that are narrow by volume but demanding in depth.
JAX leads at $223,000 (n=92, +$30K). The sample skews toward research-oriented employers at Google DeepMind, Meta AI, and similar labs, so treat it as indicative of the segment rather than a universal ML premium. C++ sits at $209,700 (n=138, +$16.7K), reflecting the inference-engineering and embedded-ML segment where latency requirements push teams below Python entirely. ONNX (an open format for exchanging ML models across frameworks and runtimes) posts at $208,600 (n=40), though the small sample makes this suggestive rather than definitive.
The next band: Transformers (the Hugging Face library for working with transformer-based models) at $202,500 (n=121, +$9.5K), Distributed Systems at $200,500 (n=154, +$7.5K), and LLMs at $200,000 (n=328, +$7K; the analytics carry two keyword variants for LLM terminology, both shown for completeness). These are skills where depth matters more than familiarity.
The common-layer premium (+$4.5K to +$6.2K):
Standard GenAI skills, major frameworks, and experimental methods cluster in a moderate band above baseline.
| Skill | US Median | vs. $193K Baseline | n |
|---|---|---|---|
| A/B Testing | $199,200 | +$6,200 | 391 |
| LLM | $198,900 | +$5,900 | 468 |
| Generative AI | $198,600 | +$5,600 | 297 |
| PyTorch | $197,500 | +$4,500 | 610 |
| Apache Spark | $197,500 | +$4,500 | 220 |
A/B Testing edging out PyTorch ($199,200 vs $197,500) is the most counterintuitive entry. The explanation: companies rigorous enough about model evaluation to list A/B testing in a job description tend to be the same companies running mature ML platforms at scale, which also happen to pay well. It is a proxy for organizational ML maturity as much as a technical skill.
Skills at or below baseline:
These are not weak skills. They are table stakes or near-table-stakes, and their flat salary curve reflects what happens when 25-70% of candidates can credibly list something: it stops differentiating compensation.
| Skill | US Median | vs. $193K Baseline | n |
|---|---|---|---|
| MLOps | $189,300 | -$3,700 | 263 |
| Python | $189,300 | -$3,700 | 905 |
| TensorFlow | $187,500 | -$5,500 | 417 |
| Deep Learning | $186,300 | -$6,700 | 408 |
| scikit-learn | $173,200 | -$19,800 | 172 |
MLOps alongside Python at -$3,700 is worth pausing on. MLOps is a genuinely difficult, modern skill set. But 25.2% of postings now list it as an expectation, which means the supply side has caught up. The skills companies are willing to pay above-market for are the ones they struggle to find, and the common tier has stopped producing that signal.
The cloud story is the same. AWS posts a US median of $177,200 (-$15,800), Google Cloud at $179,600 (-$13.4K), and Azure at $173,000 (-$20K). Cloud familiarity is nearly universal at 39% umbrella prevalence. It gets you into the conversation; it doesn't move the offer.
What Skill Families Define the Machine Learning Engineer Role?
Group every individual skill into higher-level families and count how many postings ask for at least one skill in each group.
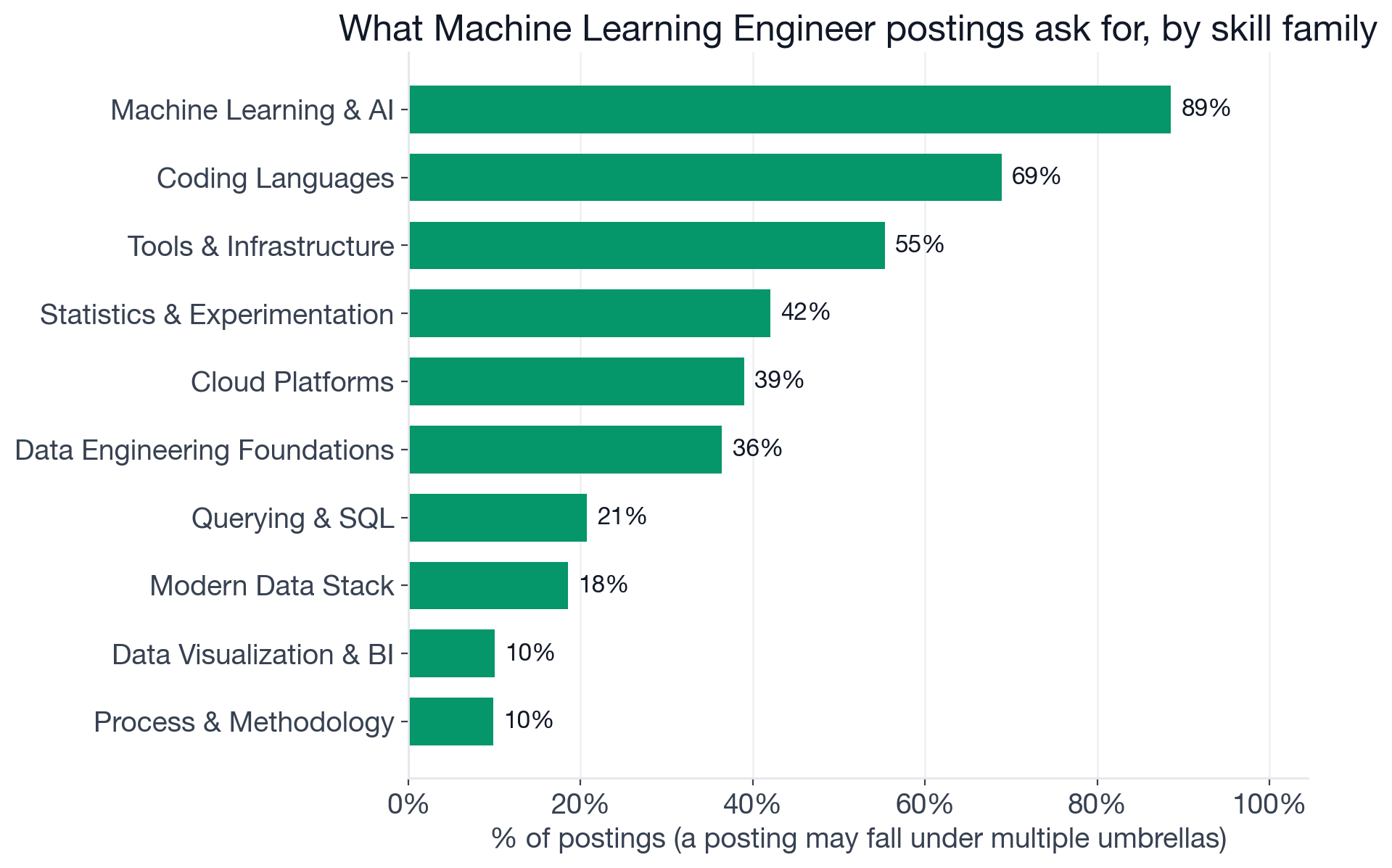
Share of Machine Learning Engineer postings that ask for at least one skill in each family. A posting that lists both PyTorch and TensorFlow counts once under "Machine Learning and AI."
The top families, ranked by share:
- Machine Learning and AI: 88.5% (ML frameworks, LLMs, MLOps, GenAI, NLP, Computer Vision)
- Production and systems layer: 74.8% (CI/CD, RAG, APIs, MLflow, LangChain, Distributed Systems, SageMaker, embeddings, vector databases)
- Coding Languages: 68.9% (Python at 66.6%, with Java and C++ as secondary options)
- Tools and Infrastructure: 55.3% (Monitoring, Kubernetes, Docker, Terraform, automation)
- Statistics and Experimentation: 42.0% (A/B Testing at 27.5%, Statistics at 16.9%)
- Cloud Platforms: 39.0% (AWS 33.7%, Azure 22.7%, Google Cloud 21.1%)
- Data Engineering Foundations: 36.4% (Data Pipelines 22.3%, Apache Spark 13.5%)
- Querying and SQL: 20.7% (SQL at 17.3%, a differentiator here, not table stakes)
That last entry is worth flagging. SQL is a table-stakes requirement in Data Engineer and Data Analyst postings. For ML Engineers, it sits at 17%, firmly in the differentiator tier. The expectation is "can write queries to pull training data," not "can design and tune a data warehouse." That distinction matters when you're allocating prep time.
The other notable family: Statistics and Experimentation at 42%. More than one in four ML Engineer postings (27.5%) explicitly asks for A/B testing. The reason is straightforward: models don't just need to be accurate offline. They need to demonstrate improvement in production experiments before broad rollout. Engineers who understand statistical testing end up driving a lot more decisions than those who stop at model accuracy metrics.
The Three Tiers of Individual Skills
Drill into individual skills and three tiers emerge based on how often they appear in postings.
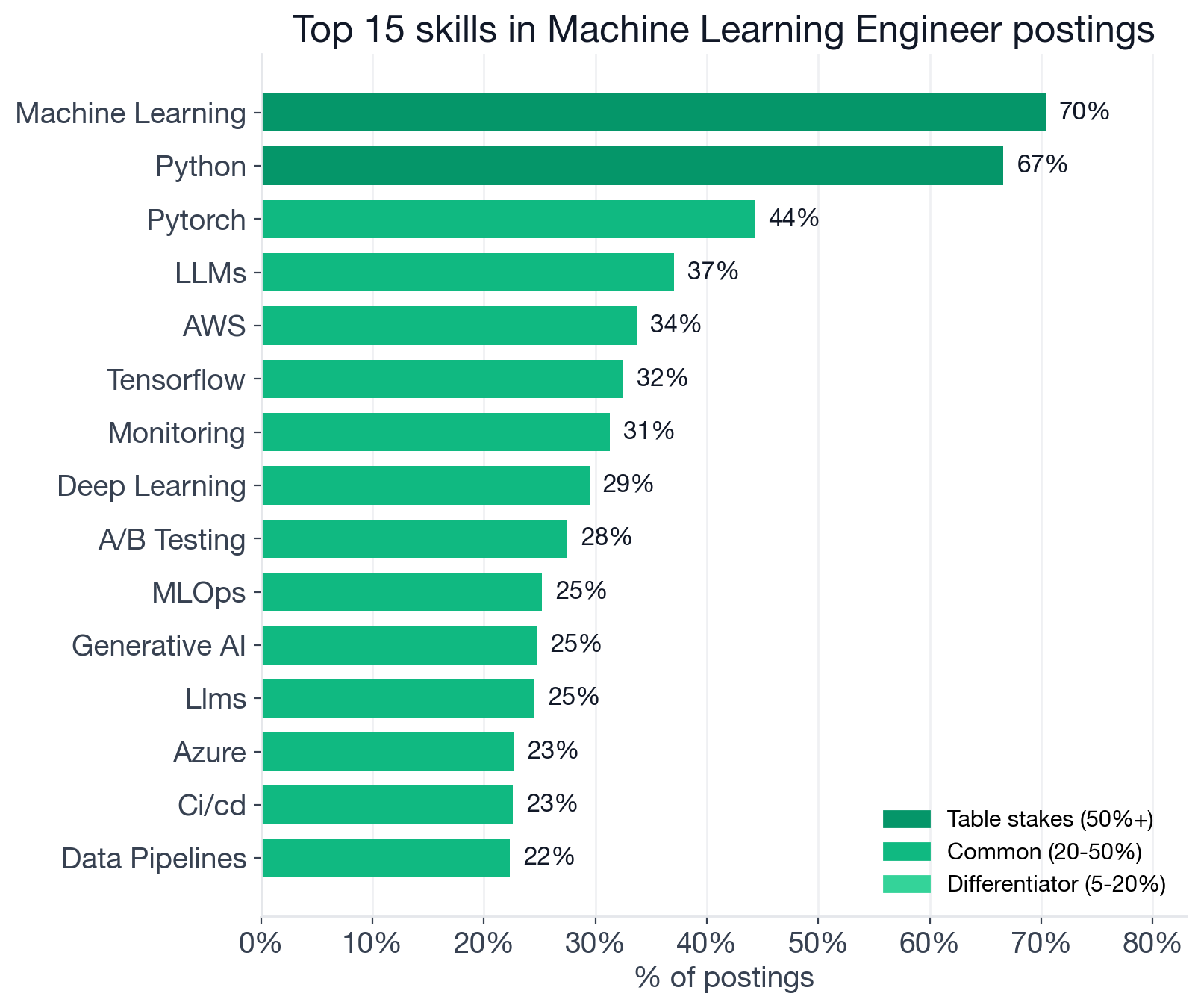
Individual skill demand in Machine Learning Engineer postings. Skills above 50% are table stakes; 20-50% are common; 5-20% are differentiators.
Table Stakes (50%+ of postings)
Two skills clear this bar:
- Machine Learning: 70.4% (browse ML Engineer openings)
- Python: 66.6% (Python-required ML Engineer openings)
Python being 66.6% and yet below the salary baseline captures the tension at the core of this role: the most common credential is no longer a differentiator. If your resume leads with Python as its headline ML skill, you're describing an entry requirement, not a competitive advantage.
Common Expectations (20-50% of postings)
Thirteen skills sit in this tier, which is unusually crowded. Together they define what a "standard" ML Engineer role looks like in 2026:
- PyTorch: 44.3%
- LLMs: 37.1%
- AWS: 33.7%
- TensorFlow: 32.5%
- Monitoring: 31.3%
- Deep Learning: 29.5%
- A/B Testing: 27.5%
- MLOps (practices for deploying, monitoring, and managing ML models in production): 25.2%
- Generative AI: 24.7%
- Azure: 22.7%
- CI/CD: 22.6%
- Data Pipelines: 22.3%
- Google Cloud: 21.1%
Two signals here deserve attention. First: LLMs (37.1%) and Generative AI (24.7%) have fully crossed from differentiator to expected. A posting that lists LLMs is describing a base expectation for one in three roles, not a specialized track. The distinction that matters now is not "do you know LLMs?" but "do you build LLM systems or just call them?"
It is worth being precise about what those percentages actually measure. They count jobs where building or fine-tuning LLM systems is an explicit requirement. They say nothing about ambient AI tool usage, the GitHub Copilot-and-ChatGPT layer that developer surveys now show reaches 84-95% of engineers across all roles. The Stack Overflow 2025 Developer Survey found 84% of developers using or planning to use AI tools; the Pragmatic Engineer's 2026 report puts weekly AI tool usage at 95% among software engineers. ML Engineers build AI systems for a living and are expected to use AI coding tools as a matter of course. The posting percentage measures the build requirement; the survey data measures the ambient expectation that goes unwritten in most job descriptions.
Second: Monitoring at 31.3%. That number is higher than most people expect. Teams that have shipped models to production have learned the hard way that deployment is a starting line, not a finish line. A model that worked well in February may be measuring something different in August as upstream data drifts.
Differentiators (5-20% of postings)
The differentiator tier is long, organized here by what kind of ML work each cluster supports:
GenAI and retrieval stack: RAG (15.6%), LangChain (9.2%, an orchestration framework for LLM applications), embeddings (5.9%), vector databases (7.3%), OpenAI API integration (7.2%). Browse ML Engineer roles that require RAG.
Infrastructure and deployment: Kubernetes (19.1%), Docker (17.6%), SageMaker (7.8%, Amazon's managed ML training and deployment service), MLflow (9.7%, a platform for ML lifecycle management covering experiment tracking, model registry, and deployment).
Domain specialties: NLP (13.9%), Computer Vision (13.1%), scikit-learn (14.1%).
Systems and compute: C++ (7.3%), Apache Spark (13.5%), Distributed Systems (7.8%).
What the Strongest Skill Pairings Signal
The co-occurrence data below identifies which skill pairs appear together more often than their individual frequencies would predict. Lift above 1 means over-representation; lift at 1 means independent; lift below 1 means anti-correlated. All figures come from the top-25 skill co-occurrence matrix.
| Skill pair | Co-occurs in | % of postings | Lift |
|---|---|---|---|
| AWS + Google Cloud | 930 postings | 18.8% | 2.63 |
| AWS + Azure | 954 | 19.2% | 2.52 |
| PyTorch + TensorFlow | 1,524 | 30.7% | 2.14 |
| Deep Learning + PyTorch | 1,008 | 20.3% | 1.56 |
| CI/CD + Python | 972 | 19.6% | 1.30 |
| Python + PyTorch | 1,851 | 37.3% | 1.26 |
| MLOps + Python | 1,038 | 20.9% | 1.25 |
Three patterns are worth unpacking.
PyTorch + TensorFlow (lift 2.14) is the most actionable for candidates. When a posting names one framework, it is more than twice as likely to also name the other compared to base rates. Companies running ML at any meaningful scale tend to have both in production, whether by historical accumulation or deliberate multi-framework strategy. "I only know PyTorch" costs interviews at these companies. You do not need equal depth in both, but you need enough TensorFlow familiarity to work in a mixed codebase.
Multi-cloud (AWS + GCP at lift 2.63, AWS + Azure at 2.52) means that when cloud skills appear in a posting at all, they usually appear in multiples. ML platforms increasingly span providers for redundancy, cost optimization, or because different parts of the stack (training vs. inference vs. data) live in different environments. A candidate with one cloud depth is competitive for most roles; the multi-cloud signal concentrates in platform-engineering and infrastructure-heavy ML work.
CI/CD + Python (lift 1.30) and MLOps + Python (lift 1.25) are the production-engineering signal. Postings that want serious Python also want the deployment discipline around it. Candidates who can talk through model versioning, deployment pipelines, canary rollouts, and rollback strategies perform better in system-design rounds than those who stop at training architecture.
Who Gets the 4.7% Entry Slice, and Who Hires Senior?
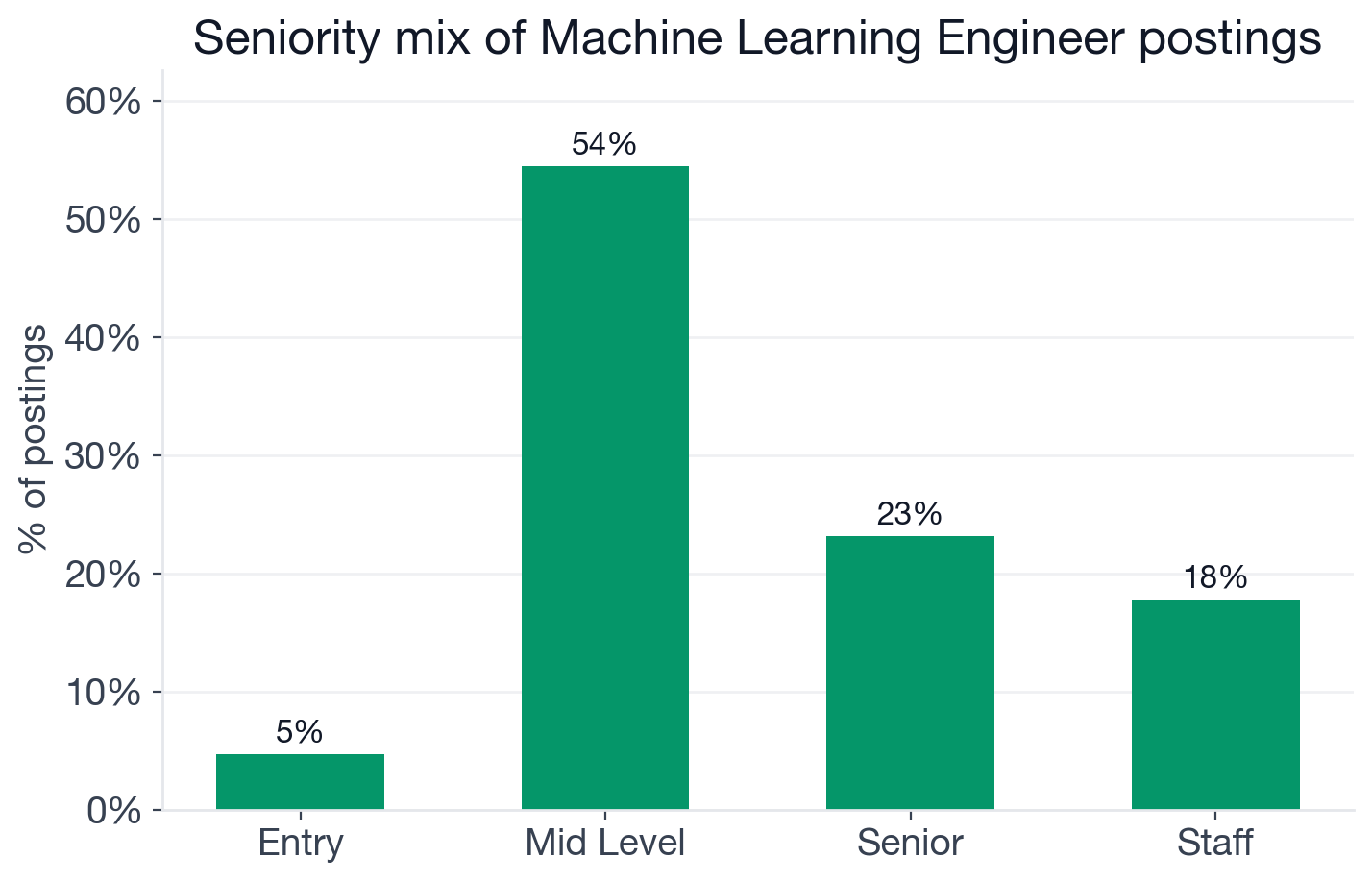
Seniority distribution of Machine Learning Engineer postings, inferred from title keywords.
- Mid-level: 54.4% (2,700 postings)
- Senior: 23.1% (1,147) (senior ML Engineer openings)
- Staff / Principal / Lead: 17.8% (881)
- Entry: 4.7% (232)
Fewer than 1 in 20 open ML Engineer positions is genuinely entry-level. Companies expect incoming engineers to have shipped at least one model to production, which makes the direct-entry path narrow. The most practical routes in are through adjacent roles where you can accumulate the deployment reps first: Data Scientist (modeling and experimentation experience), Software Engineer (production deployment experience), or a graduate research position (systems depth).
The staff tier at 17.8% is high relative to most tech roles, and it reflects a real career structure. ML Engineering has a well-defined IC track above senior: engineers who can design the ML platform architecture, own model infrastructure decisions, and mentor teams are genuinely in demand. The salary premium data confirms this: the skills concentrated at the staff layer (distributed systems, C++, systems design) are exactly the ones commanding the highest compensation.
Where the Jobs Are, and Whether You Can Work Remotely
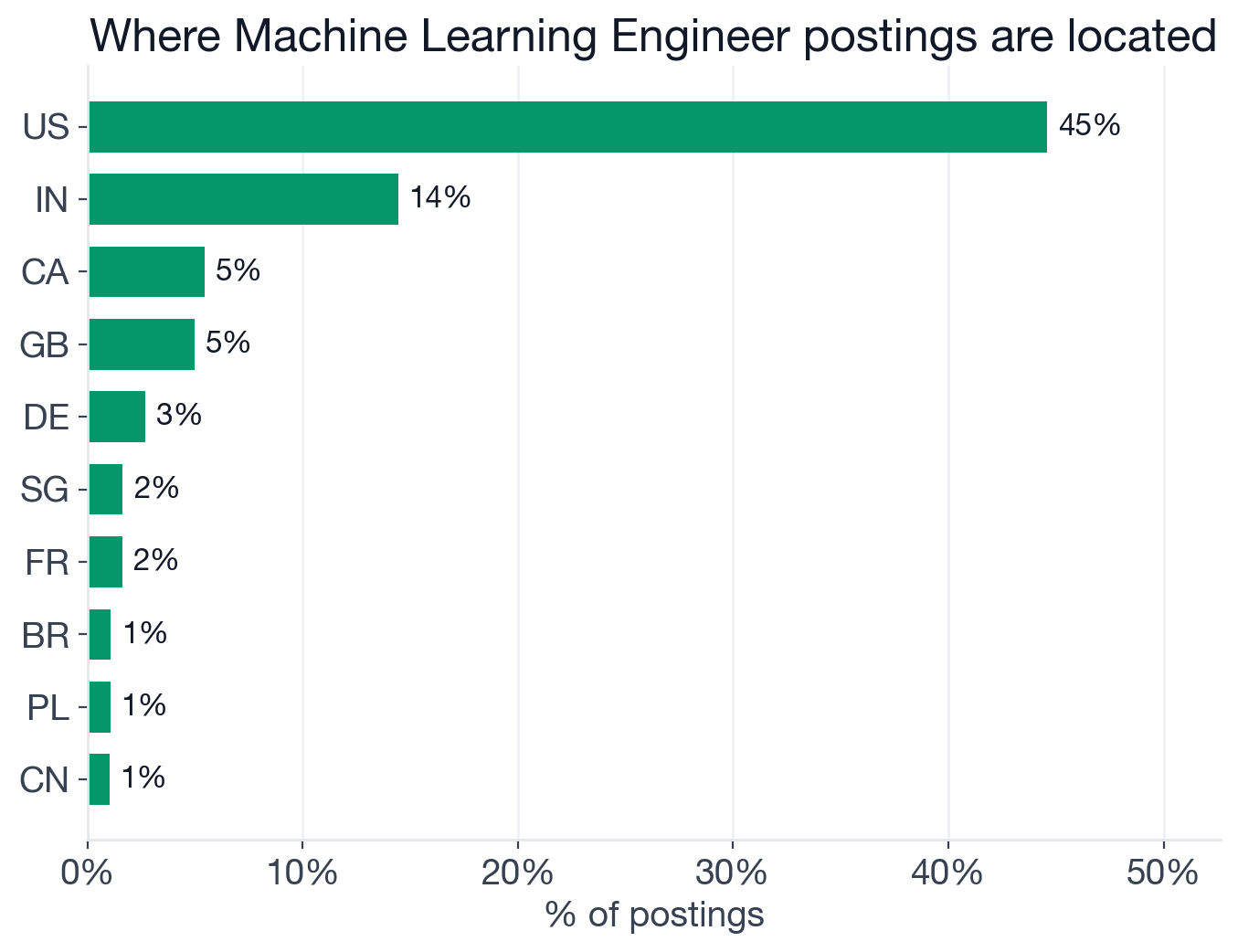
Top countries by share of active Machine Learning Engineer postings.
- United States: 44.6% (2,212 postings) (US-based ML Engineer openings)
- India: 14.4%
- Canada: 5.4%
- United Kingdom: 5.0%
- Germany: 2.7%
The US share at 44.6% is unusually high. For comparison, data engineering roles show substantially lower US concentration. If you are US-based, the ML Engineer market is deeper and more concentrated around you than almost any other technical role.
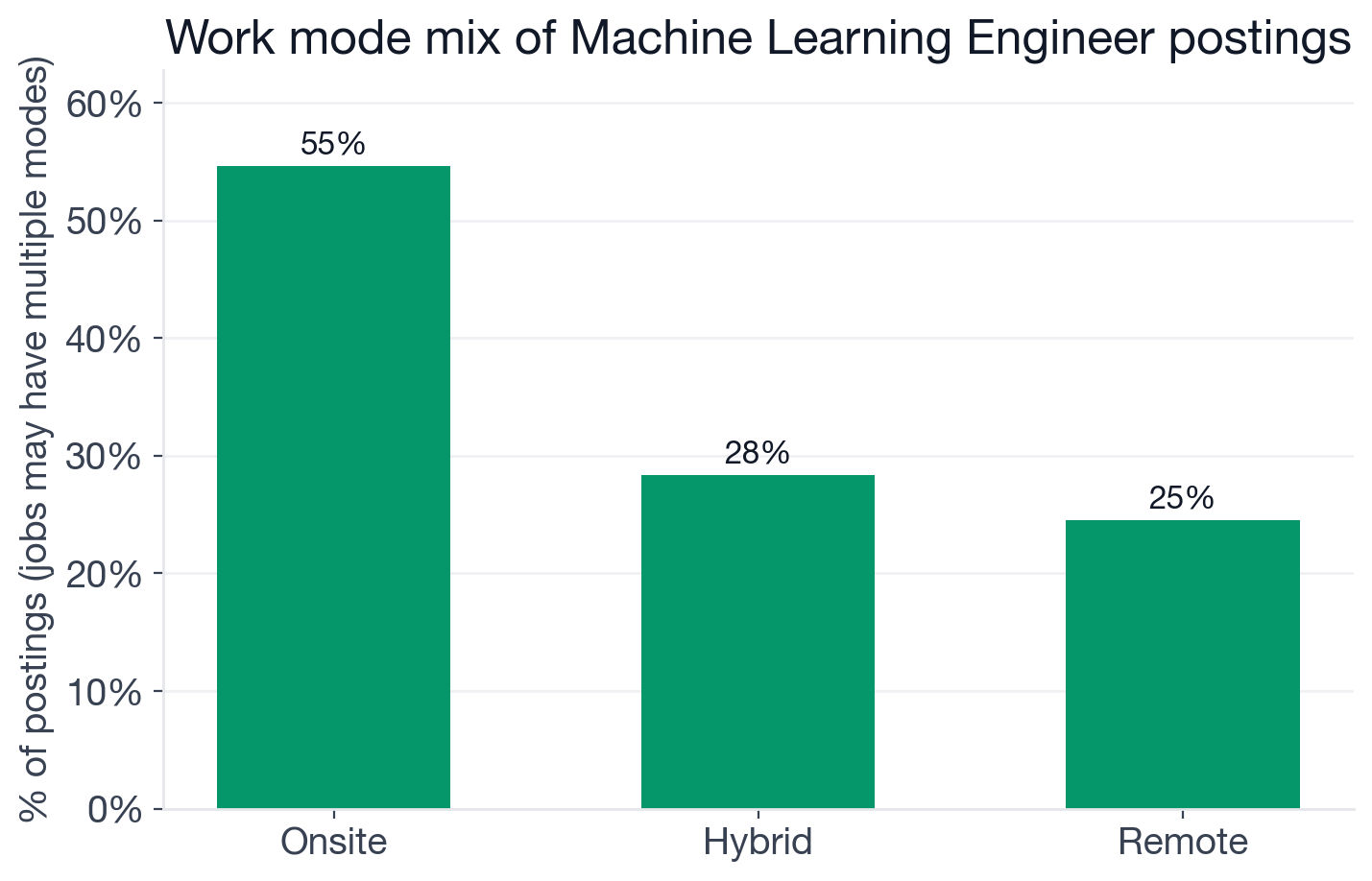
Share of Machine Learning Engineer postings tagged with each work mode. Some postings carry multiple tags.
- Onsite: 54.6% of postings (2,709)
- Hybrid: 28.4% (1,407)
- Remote: 24.6% (1,218) (fully-remote ML Engineer openings)
The remote share (24.6%) is lower than most people expect for a field this technical. The highest-paying segment of the market (hardware companies, research labs, autonomous vehicle teams) requires physical access to GPUs, hardware labs, and in-person research collaboration. The remote segment concentrates in SaaS companies, fintech, and enterprise software. If remote is a firm requirement, the effective pool shrinks from roughly 4,900 to roughly 1,200 postings.
Who's Hiring in 2026?
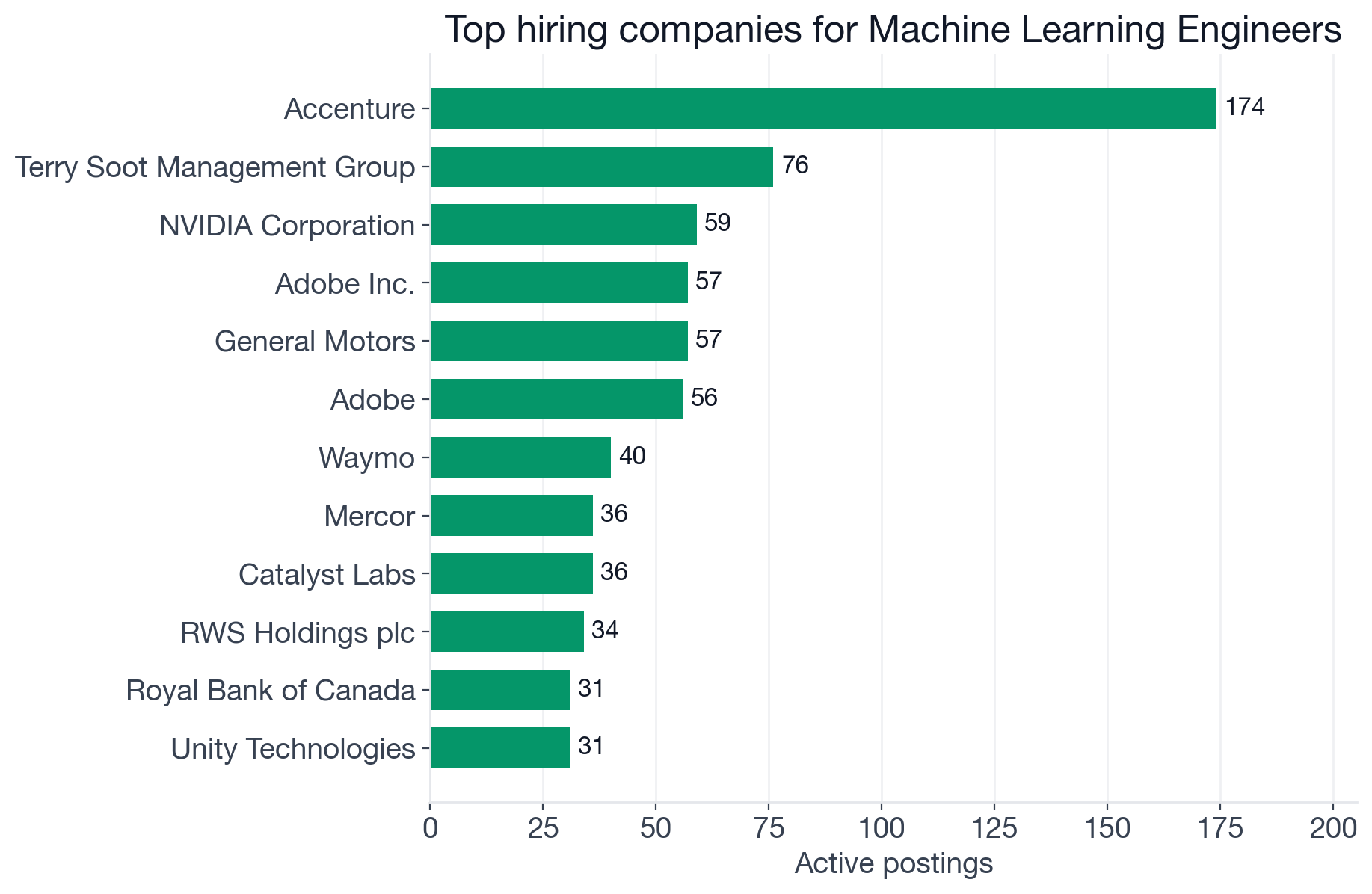
Top companies by active Machine Learning Engineer postings (distinct openings).
| Company | Active postings | Segment |
|---|---|---|
| Accenture | 174 | Consulting |
| Adobe | ~113 | Software / media |
| NVIDIA | 59 | Semiconductor / AI infrastructure |
| General Motors | 57 | Automotive / autonomy |
| Waymo | 40 | Autonomous vehicles |
| Royal Bank of Canada | 31 | Finance |
| Unity Technologies | 31 | Game engine / real-time 3D |
| Spotify | 31 | Consumer tech |
| Autodesk | 30 | Design software |
| Booz Allen Hamilton | 28 | Government consulting |
| PricewaterhouseCoopers | 28 | Consulting |
| Coupang | 27 | E-commerce |
Accenture's volume reflects the consulting-and-services pattern common across all ML and data roles: large firms maintain high posting counts to support client deployments, often at salary levels below pure-product employers. NVIDIA, Waymo, and General Motors are the hardware and autonomy segment, where the C++ and systems-depth premiums described earlier apply most directly. Spotify, Unity, and Autodesk are product-led tech companies focused on recommendations, real-time rendering, and design AI. Royal Bank of Canada and Coupang represent the finance and e-commerce segments where ML is core infrastructure.
For company-specific interview formats and what each firm prioritizes in its ML Engineering rounds, the interview preparation guides break down the process by company.
How to Use This in Your Job Search
The clearest signal from this dataset: ML Engineering rewards depth-first progression, not breadth-first.
Build the table stakes, then commit to one depth axis. Python and ML fundamentals are filters, not differentiators. The premium skills (JAX, C++, distributed systems, Transformers) do not require knowing all of them. Pick one depth axis: research engineering (JAX, GPU programming, custom CUDA kernels), inference engineering (C++, ONNX, model compression and quantization), or production ML (distributed training, model monitoring at scale, feature stores). The salary data shows each path pays measurably above the framework tier.
Add experimental rigor. A/B Testing at $199,200 outearning PyTorch at $197,500 is a direct signal from hiring managers: engineers who can design, run, and interpret production model experiments are valued above engineers who can only build models. Drill A/B testing and experimentation topics in the question bank so you can speak to it fluently in the interview, not just list it on a resume.
Practice the full round, not just the concepts. ML Engineer interviews typically include ML system design (training pipelines, feature stores, model serving architecture), coding (often algorithm-heavy), and ML fundamentals (optimization, regularization, evaluation metrics). AI mock interviews let you run the full round with on-demand feedback, which is where the gap between "I know this" and "I can perform this under pressure" closes.
Route in through adjacent roles if you're early. The 4.7% entry-level share means the direct door is narrow. Data Scientist, Software Engineer, and graduate ML research positions are the practical side doors: they build production reps and systems depth that make the ML Engineer move straightforward. Browse current openings on the InterviewStack.io job board and use the seniority filter to find mid-level roles whose requirements match your actual experience.
Build foundations with interactive courses in ML theory, statistics, system design, and algorithms before you start applying. The interview at NVIDIA or Waymo tests different things than the round at an enterprise SaaS company; make sure your prep matches the segment you are actually targeting.
FAQ
Q. What skills do companies want for Machine Learning Engineer roles in 2026?
Machine Learning (70.4%) and Python (66.6%) are table stakes. Above that, PyTorch (44.3%), LLMs (37.1%), AWS (33.7%), TensorFlow (32.5%), Deep Learning (29.5%), A/B Testing (27.5%), and MLOps (25.2%) sit in the common tier. LLMs and Generative AI are no longer differentiators: they appear in 37% and 25% of postings respectively, solidly in the expected layer.
Q. What is the median salary for a Machine Learning Engineer in 2026?
The median US base salary is $193,000 across 1,272 postings with US salary data disclosed. Equity, bonuses, and sign-on are not in this figure, so total compensation at top employers runs meaningfully higher.
Q. Which Machine Learning Engineer skills pay the highest premium in 2026?
Among US postings, the largest premiums attach to research and systems-depth skills. JAX commands a $223,000 median ($30K above baseline, n=92). C++ sits at $209,700 (+$16.7K, n=138). Transformers reaches $202,500 (+$9.5K, n=121), and Distributed Systems hits $200,500 (+$7.5K, n=154). By contrast, Python posts at $189,300 (below baseline) and TensorFlow at $187,500 (below baseline), showing that the common framework tier does not command a premium.
Q. Is Machine Learning Engineer a good entry-level role to break into?
It is one of the harder roles to enter from scratch. Only 4.7% of postings are entry-level (232 of 4,960). The dominant tier is mid-level at 54.4%, with senior at 23.1% and staff at 17.8%. Most hiring managers expect candidates to have shipped at least one ML system to production before applying.
Q. Where are Machine Learning Engineer jobs located, and how remote-friendly are they?
The US leads at 44.6% of postings (2,212), followed by India (14.4%), Canada (5.4%), and the UK (5.0%). Of all postings globally, 54.6% are onsite, 28.4% are hybrid, and 24.6% are remote.
Q. What is the dominant Machine Learning Engineer skill stack in 2026?
The base stack is Machine Learning plus Python, appearing together in 53.1% of postings (lift 1.13). The most over-represented pair is PyTorch plus TensorFlow at lift 2.14, appearing in 30.7% of postings, signaling that companies want engineers who can work in both frameworks, not just one. Multi-cloud fluency is also overrepresented: AWS plus Google Cloud co-occurs at lift 2.63, and AWS plus Azure at lift 2.52.
Q. How has the LLM and GenAI wave changed what ML Engineers need to know?
LLMs (37.1%) and Generative AI (24.7%) have moved into the common tier of ML Engineer skills: expected but not differentiating. The role now spans classic ML engineers (PyTorch, TensorFlow, deep learning, MLOps) and GenAI-era engineers who build retrieval pipelines (RAG), fine-tune large models, and deploy LLM services. Both skill sets are common-tier; the salary premium still sits at the systems and research layer above both.
The Layer That Matters
The ML Engineer hiring market in 2026 has a clear shape: a broad base of Python and framework skills that most applicants can demonstrate, a now-standard GenAI layer that has moved from differentiator to expectation over the past two years, and a thinner upper tier of systems depth where the real salary signal lives. Getting from the base to the top is a depth question, not a breadth question. One domain you have gone deep on (inference systems, distributed training, model evaluation at scale, research-grade numerical computing) will move your offer more than three additional frameworks you have briefly touched. The market is pricing that clearly.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.