What Has the LLM Era Added to the Data Scientist Job Description?
For years, "Data Scientist" meant one thing: build ML models, run A/B tests, write Python. The job posting from 2022 looked like this: Python, scikit-learn, SQL, maybe TensorFlow, communicate findings to stakeholders. That description still exists, and it still pays well. But a different version of the job has grown up beside it, one where the ML model is an LLM, the pipeline runs RAG retrieval instead of batch inference, and the role involves orchestrating AI agents as much as building classifiers from scratch.
We looked at every active Data Scientist posting on the InterviewStack.io job board as of May 2026, 3,889 listings, with AI skill mentions extracted and categorized by generation (traditional ML versus new-wave generative AI from 2023 onward). The headline splits in two directions at once: 83.7% of postings mention some form of AI, but within that, 39.6% now explicitly require new-wave generative AI skills that barely appeared in job descriptions three years ago.
That 39.6% figure understates the actual shift. It counts only postings that explicitly list LLMs, RAG, AI Agents, or LangChain as requirements: companies hiring Data Scientists to build AI systems. It says nothing about the ambient layer that employer surveys and developer data capture. According to JetBrains' April 2026 report, 90% of developers regularly use at least one AI tool at work. The GitHub Copilot, the ChatGPT-assisted analysis, the AI-generated notebook scaffolding that most working Data Scientists use daily: none of that shows up in a job description. The 39.6% measures depth of AI responsibility. The floor has risen for everyone.
Key Findings
- 3,889 active Data Scientist postings analyzed on the InterviewStack.io job board as of May 2026.
- 83.7% of postings mention AI of some kind: 79.5% require traditional ML or deep learning; 39.6% explicitly require new-wave generative AI skills (LLMs, RAG, AI Agents, LangChain).
- Machine Learning leads all AI skills at 77.8% of postings; among gen AI skills, Generative AI (20.1%), LLMs (19.8%), AI Agents (17.1%), and RAG (14.3%) are the fastest-growing requirements.
- Energy leads all industries at 93.3% AI adoption, followed by retail (52.3%), finance (49.2%), and technology (48.0%).
- The US salary signal is counterintuitive: postings requiring new-wave AI skills show a median US base of $125,000 (n=343), versus $133,050 (n=152) for postings with no AI at all.
- Junior-level postings have the highest gen AI rate at 55.8%, above mid-level (36.9%), senior (39.0%), and staff (42.2%).
- The US accounts for 40.7% of all postings, but India (58.0% AI rate) and the UAE (89.7% AI rate) lead on AI intensity within their markets.
What Did the Data Scientist Job Look Like Before the LLM Era?
In 2021 and 2022, the canonical Data Scientist job was a statistical modeling role with Python and SQL at the center. A typical posting asked for regression and classification experience, familiarity with scikit-learn or XGBoost, possibly deep learning if the company had the volume of data for it, and the ability to communicate results to non-technical stakeholders. Model deployment was often someone else's problem: the Data Scientist handed off a trained model, and a platform team took it from there.
The generative AI wave changed what "doing data science" means in practice. MIT Sloan's 2026 data science trends review captures the shift: "The job title is the same, but the work isn't; orchestrating agents and designing guardrails has replaced executing every step by hand." (MIT Sloan Management Review, Five Trends in AI and Data Science for 2026) The model training loop that once defined the role now competes with retrieval-augmented generation pipelines, fine-tuned LLMs, and agentic workflows that call tools, branch on outputs, and route decisions without a human in the loop.
This transition also shows up in the ecosystem around the role. AI/ML Engineer postings grew 143% year-over-year according to Data Science Collective's 2026 job market analysis, a sister role to Data Scientist that signals how rapidly the boundary between data science and AI engineering is dissolving. Python, the lingua franca of data science, is also the primary language of the AI tooling ecosystem, meaning Data Scientists are the cohort best positioned to absorb the shift without retraining the core of their stack.
The Stack Overflow Developer Survey 2025 finds 51% of professional developers using AI tools daily. For Data Scientists, who live inside Python and Jupyter notebooks, the penetration is almost certainly higher. Employers know this and do not list it. The job description lists what is non-standard; it does not list what is assumed.
What Do Companies Explicitly Require From Data Scientists Now?
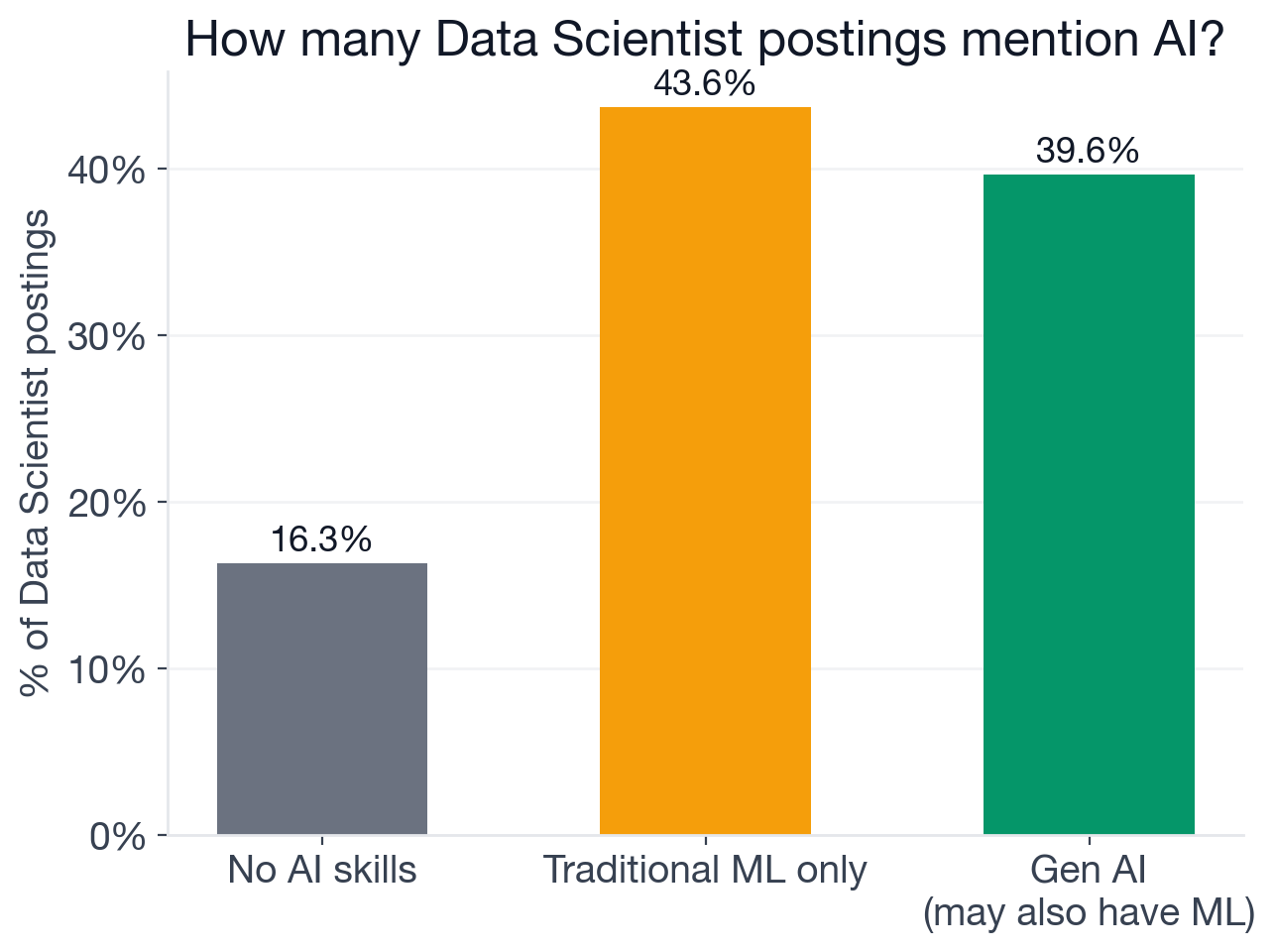
Share of 3,889 active Data Scientist postings that mention traditional ML, new-wave generative AI, or both.
Traditional ML (Machine Learning, Deep Learning, Transformer Models) appears in 79.5% of Data Scientist postings: this has been the baseline for most of the past decade. New-wave generative AI (LLMs, Generative AI, RAG, AI Agents, LangChain, Prompt Engineering, Vector Databases) appears in 39.6% of postings, a share that was essentially zero before 2023. About 35.8% of postings ask for both, the most common pattern for gen AI Data Scientist roles: employers want someone who can build a retrieval pipeline and also has the ML fundamentals to reason about model behavior, evaluation, and failure modes.
Only 3.8% of postings ask for gen AI with no traditional ML foundation at all. The field is not abandoning classical ML; it is layering generative AI on top of it. What that means for candidates is that skipping the statistical and ML foundations to learn LangChain in isolation is exactly backwards.
What the data cannot show is the ambient layer: roughly 90% of developers regularly use at least one AI tool at work (JetBrains, April 2026) without that usage appearing anywhere in their job description. Every Data Scientist working in 2026 is operating with AI-assisted workflows. The job posting reflects what is an explicit, differentiating requirement. Everything else is assumed.
Which AI Skills Are Reshaping the Data Scientist Role?
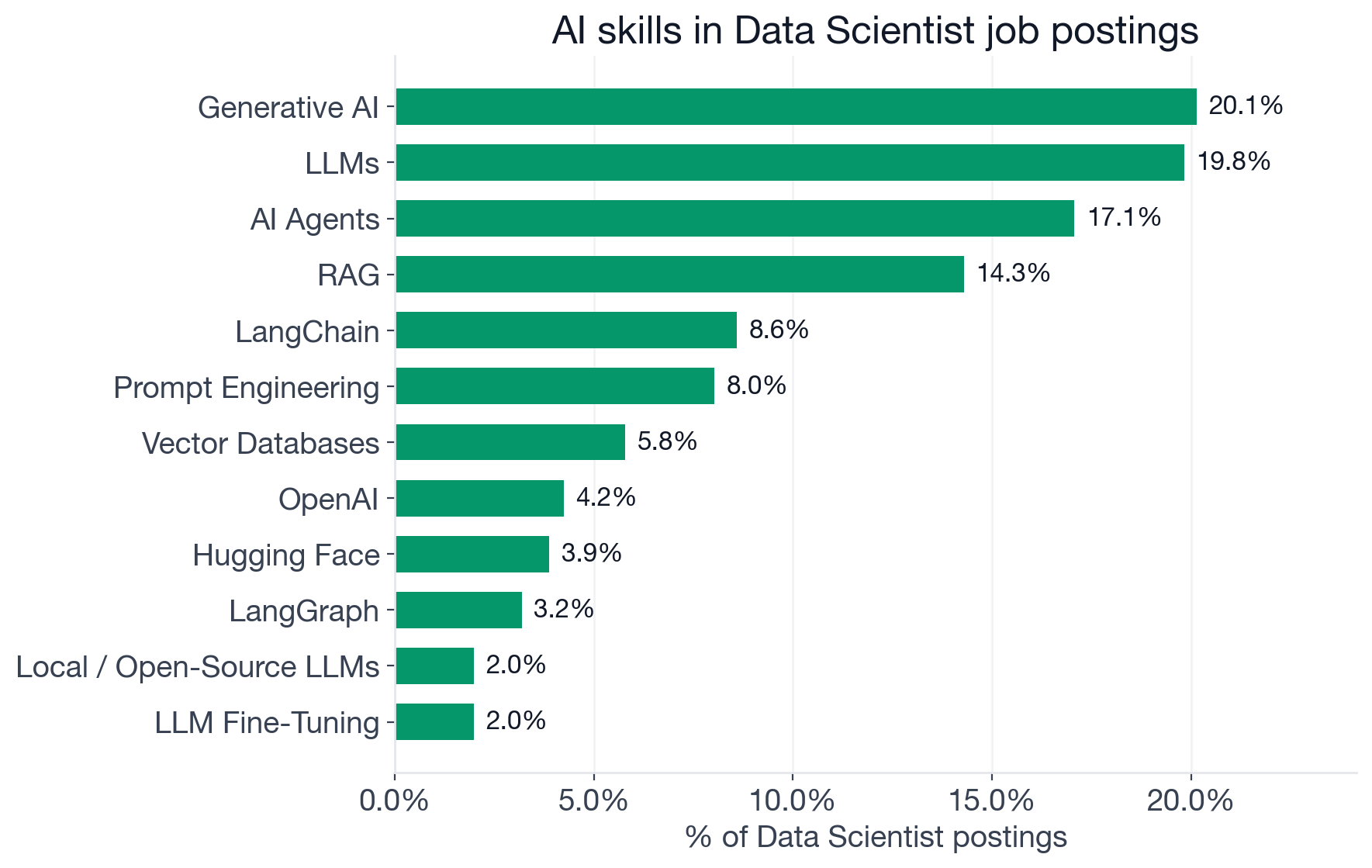
Percentage of 3,889 Data Scientist postings that mention each AI skill. Skills marked "new-wave" emerged in or after 2023.
Machine Learning (77.8%) and Deep Learning (32.1%) are the inherited foundation, present in Data Scientist postings long before the generative AI era. The fastest-growing requirements cluster in two tiers worth understanding separately: new-wave generative AI skills, and MLOps (a growing operational discipline that predates gen AI but has accelerated with LLM production deployments).
The 15-20% tier: expected at many companies now
Generative AI (20.1%) and LLMs (19.8%) now appear in roughly one in five Data Scientist postings. These are not niche signals. They represent companies that have integrated language model capabilities into their data science work as a standing expectation, not a specialization. MLOps (18.8%), the set of practices for deploying and monitoring ML models reliably in production, is growing because LLMs in production are operationally more complex than traditional batch models: they drift, hallucinate, and require evaluation frameworks that classical model monitoring does not cover.
AI Agents (17.1%) is the fastest-moving entry on this list. Orchestrating systems where models collaborate, route decisions, and call external tools autonomously was essentially absent from Data Scientist job descriptions in 2022. It now appears in nearly one in six postings, and the Data Scientist openings that list AI Agents tend to be the most engineering-intensive in the role category. RAG, or Retrieval-Augmented Generation (a pattern for grounding LLM responses in a company's own data rather than relying on training knowledge alone), appears in 14.3% of postings and has become the dominant architectural pattern for enterprise AI products that Data Scientists build and maintain.
The 5-10% tier: differentiators worth building now
LangChain (a Python framework for building LLM-powered applications, appearing in 8.6% of postings) and its graph-based extension LangGraph (a tool for building stateful, multi-step agent workflows, appearing in 3.2%) are framework-specific requirements: companies that list them have made an explicit architectural choice and want practitioners who know the toolchain. Prompt Engineering (8.0%) shows up explicitly in companies where Data Scientists own the interaction and evaluation layer, not just the underlying model. Vector Databases (5.8%) are the storage layer for RAG and embedding-based search; one in seventeen postings requires them, enough to be a meaningful differentiator for candidates targeting gen AI roles. Data Scientist openings that require RAG almost always combine it with LLMs and vector database skills as a coherent stack.
The combined picture: traditional ML fluency is still the entry ticket, and the second layer of requirements now runs through the generative AI stack. A Data Scientist who cannot speak to LLM evaluation, RAG architecture tradeoffs, or basic agent orchestration is missing a growing share of what interviewers will probe.
Does Working With AI Raise Data Scientist Salaries?
Among US postings where salary is disclosed, the numbers break differently than you might expect. All figures are US base salary only: equity, RSUs, bonuses, and sign-on are not captured in job posting data, and total compensation at top-tier employers is meaningfully higher than what we report here, particularly at AI-native companies where equity structures are aggressive.
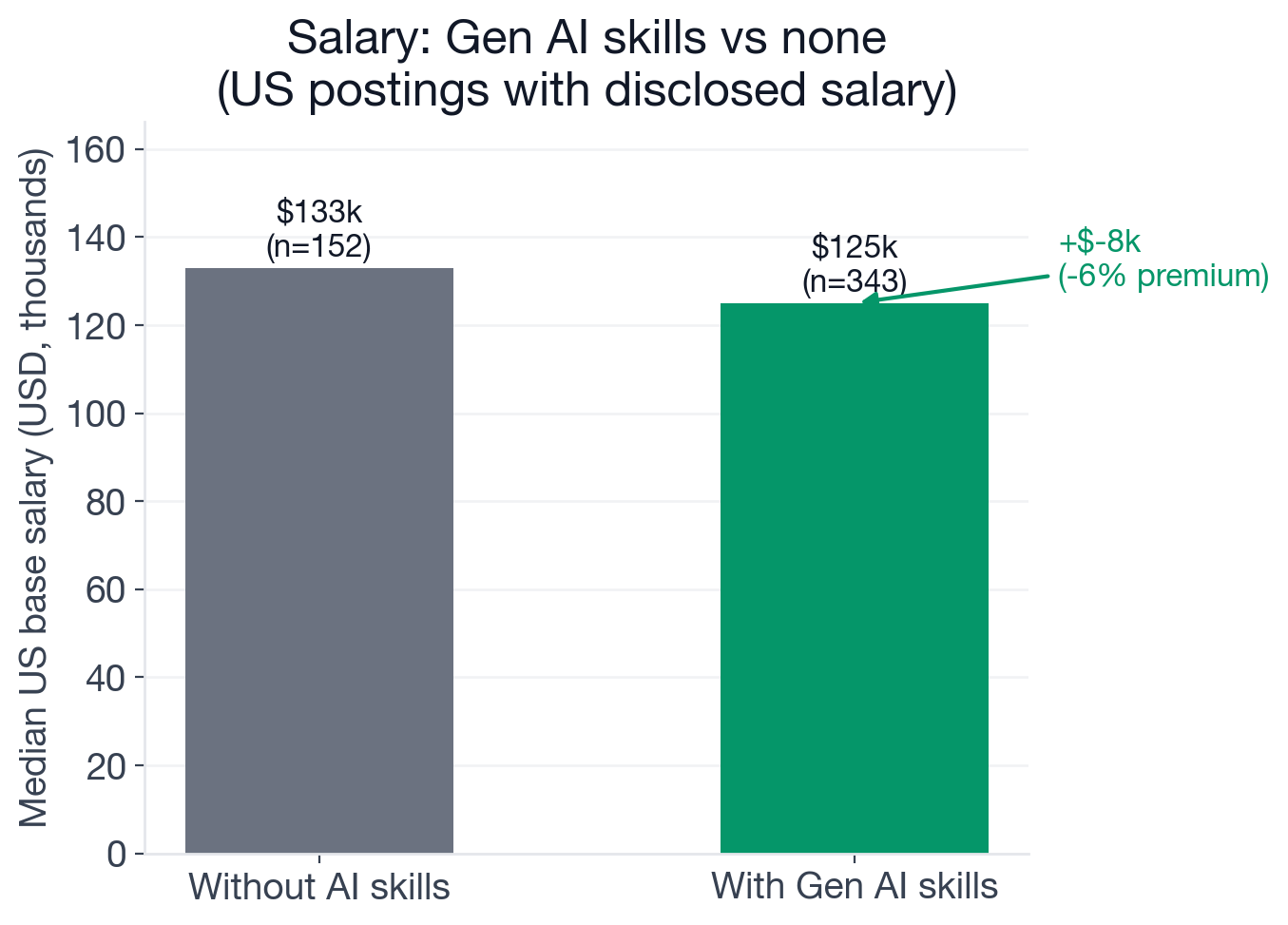
Median US base salary for Data Scientist postings with new-wave generative AI requirements versus those with no AI requirements. US postings with disclosed base salary only.
Postings that require new-wave AI skills carry a median US base of $125,000 (n=343). Postings with no AI requirements at all carry a median of $133,050 (n=152), a gap of about $8,000 in favor of the non-AI group.
The explanation is structural, not a paradox. The 152 "no AI" postings are heavily concentrated in classical quantitative roles at financial services firms, pharma companies, and insurance: actuarial modeling, credit risk, clinical trial statistics. These roles pay a premium for rigor and domain depth, and their employers have little reason to list LLMs in the job description because the work genuinely does not involve them. The 343 gen AI postings skew toward tech and product companies, where equity is a significant part of the total offer but does not appear in the base salary number captured in a job posting.
The practical read: someone choosing between a $133K base in classical statistical modeling at a finance firm and a $125K base in an LLM pipeline role at a tech company is not taking an $8K pay cut. They are making a bet on equity trajectory and the type of work they want to own. Neither path is wrong; the salary data just reflects two genuinely different employer profiles, not a penalty for learning gen AI.
Who Leads the AI Shift in Data Science?
Which seniority levels are most affected?
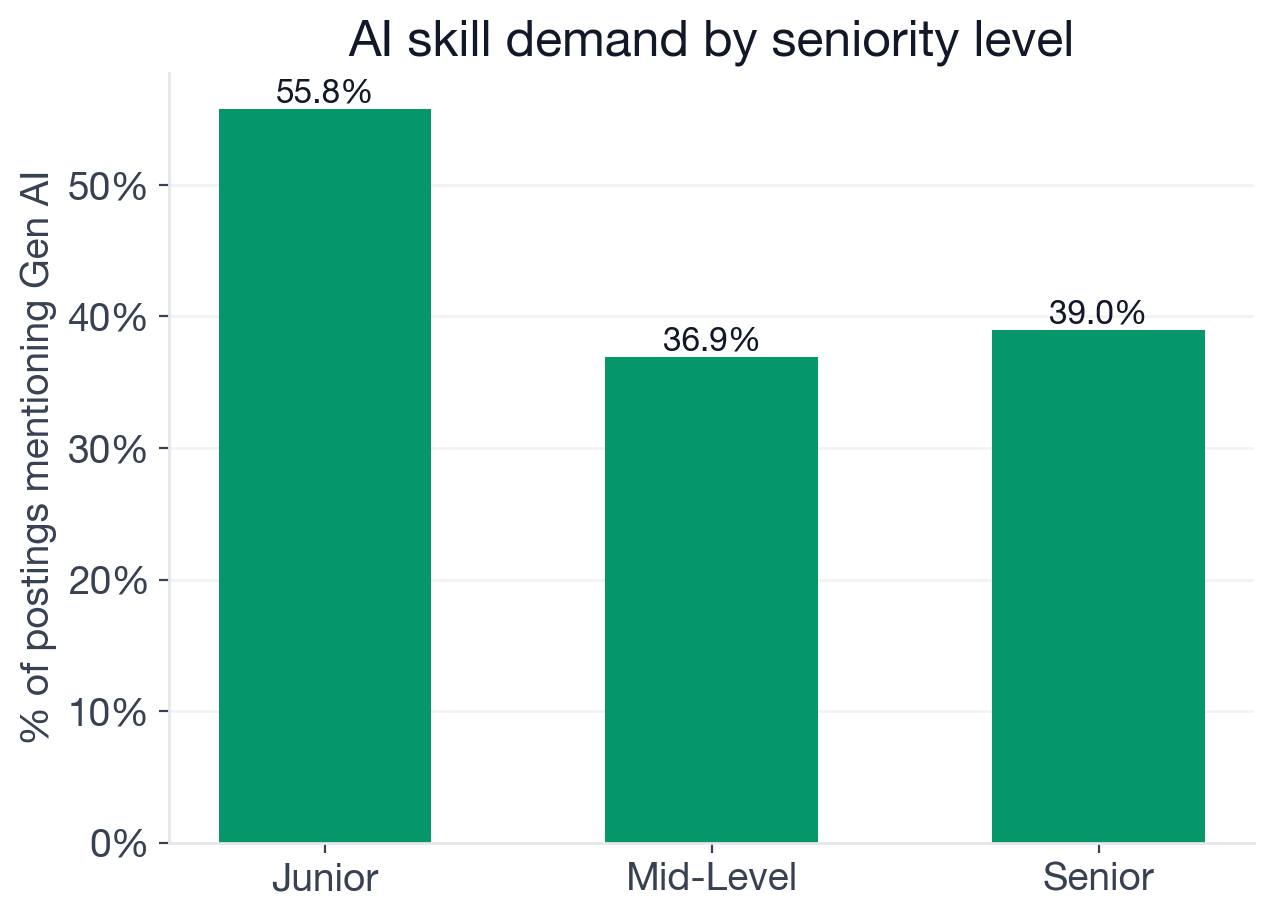
Share of Data Scientist postings at each seniority level that explicitly require new-wave generative AI skills.
Junior postings lead at 55.8%, well above senior (39.0%), mid-level (36.9%), and even staff (42.2%). More than half of all junior Data Scientist postings now explicitly list generative AI as a requirement. Entry-level sits lower at 28.6%, likely because entry postings still emphasize foundational skills over specific frameworks.
The junior intensity reveals something about hiring strategy: companies are not only upskilling existing Data Scientists into gen AI. They are rebuilding the junior pipeline with AI-native expectations from the first hire. For anyone entering the market at a junior level, the implication is clear. Gen AI fluency is no longer a differentiator at that level; it is a baseline filter.
Senior roles at 39.0% are still heavily weighted toward traditional ML: the data reflects that companies value deep statistical expertise and production ML experience at senior levels, with gen AI layered on top rather than substituted in. Staff roles at 42.2% sit slightly above senior, consistent with the expectation that staff Data Scientists are shaping architecture decisions where gen AI capabilities are increasingly central.
Which industries are moving fastest?
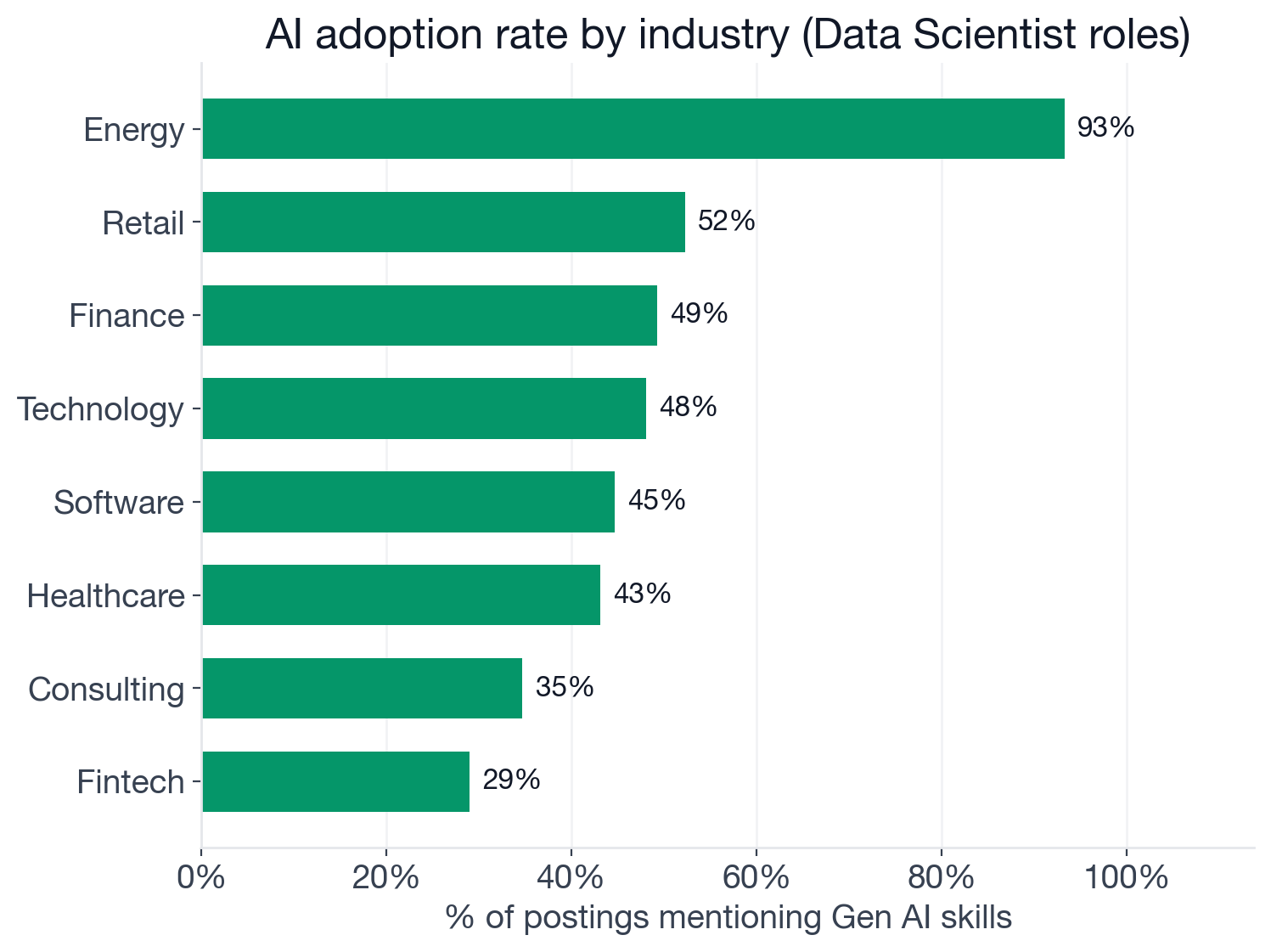
Share of Data Scientist postings in each industry that mention new-wave generative AI skills.
Energy leads all industries at 93.3%, driven substantially by Cobblestone Energy, which runs 103 active Data Scientist postings all requiring AI skills, a signal that energy trading and analytics firms are treating gen AI capabilities as non-negotiable. Retail (52.3%), finance (49.2%), and technology (48.0%) form the next tier, sectors where customer-facing AI applications, fraud detection, and recommendation systems create high demand for Data Scientists who can work with generative models.
Fintech (29.0%) is the outlier at the low end, likely reflecting regulatory pressure toward interpretable, auditable classical models in credit and lending decisions, where black-box LLM outputs carry compliance risk.
Geographically, India (58.0% AI rate across 410 postings) and the UAE (89.7% AI rate across 116 postings) post higher AI adoption rates than the US (33.6% across 1,581 postings). Both markets are leaning into gen AI Data Scientist capabilities faster than the US market in aggregate, a pattern consistent with the Informatica CDO Insights 2026 finding that nearly 7 in 10 organizations have now adopted GenAI globally.
Who is hiring?
| Company | Total Postings | AI Postings | AI Rate |
|---|---|---|---|
| Cobblestone Energy | 103 | 103 | 100% |
| Booz Allen Hamilton | 77 | 23 | 30% |
| RELX Group | 65 | 53 | 82% |
| IQVIA | 63 | 30 | 48% |
| OpenAI | 24 | 24 | 100% |
| Walmart Inc. | 30 | 18 | 60% |
| Micron Technology | 35 | 17 | 49% |
| PricewaterhouseCoopers | 42 | 32 | 76% |
| Manulife Financial Corporation | 14 | 13 | 93% |
| Royal Bank of Canada | 22 | 14 | 64% |
| Johnson & Johnson | 15 | 10 | 67% |
| Binance | 16 | 12 | 75% |
The list spans sectors and signals. RELX Group and IQVIA are both information services companies (legal and health data, respectively) where AI-powered search, summarization, and evidence synthesis are core product directions, explaining their high AI rates. PwC at 76% reflects the consulting firm's push to sell AI-augmented analytics services to clients. Booz Allen Hamilton at 30% is lower because a significant share of its Data Scientist work sits in government and defense contexts where gen AI adoption lags commercial markets.
How to Use This in Your Job Search
The clearest signal from this data is that the entry-level bar has moved. If you are coming into the market at a junior level, more than half of postings now explicitly expect gen AI skills. If you are a senior practitioner, 39% of postings layer gen AI on top of traditional ML requirements that were already demanding.
Start with the ambient layer before targeting the explicit one. Adopt AI-assisted workflows in your current work, GitHub Copilot, ChatGPT for data analysis scaffolding, AI-assisted code review, regardless of whether your job description mentions it. This is not about getting credit; it is about keeping pace with what interviewers will assume you are doing. Then build toward the explicit layer: a portfolio project that demonstrates RAG, LLM evaluation, or agent orchestration directly addresses the 14 to 20% of postings requiring those skills. Filtering Data Scientist openings by Generative AI or LLMs is a fast way to scope roles where that investment pays off most immediately.
The interview questions have shifted alongside the job descriptions. Traditional Data Scientist rounds centered on model selection, statistical inference, and experimental design. Gen AI roles now test RAG architecture tradeoffs, LLM evaluation strategies, and how to build agent systems safely and reliably. Practice with AI mock interviews to stress-test both the classical ML topics and the newer gen AI scenarios that are entering onsite rounds. Use the question bank to drill specific areas, and the interactive courses to fill gaps in foundational ML and the modern AI stack that the data shows hiring managers still require. Browse all active Data Scientist openings and apply skill filters to match your current strengths and the direction you are building toward.
FAQ
Q. What share of Data Scientist postings explicitly require AI skills in 2026?
83.7% of the 3,889 active Data Scientist postings analyzed mention some form of AI: 79.5% require traditional ML or deep learning, and 39.6% explicitly require new-wave generative AI skills such as LLMs, RAG, AI Agents, or LangChain. Only 16.3% of postings mention no AI keywords at all.
Q. Which AI skills appear most in Data Scientist postings in 2026?
Machine Learning tops the list at 77.8% of postings, followed by Deep Learning at 32.1%. Among new-wave generative AI skills, Generative AI (20.1%) and LLMs (19.8%) lead, followed by AI Agents (17.1%), RAG (14.3%), LangChain (8.6%), and Prompt Engineering (8.0%). Vector Databases appear in 5.8% of postings. MLOps (18.8%), the practice of deploying and monitoring ML models reliably in production, also ranks highly; it predates the generative AI era but its demand is accelerating because LLMs in production require more rigorous evaluation and drift monitoring than traditional batch models.
Q. Do Data Scientist postings with gen AI skills pay more than traditional ones?
Counterintuitively, no. Among US postings with disclosed salary, those requiring new-wave AI skills show a median of $125,000, while postings without any AI requirements show $133,050. Classical statistical roles at financial services, pharma, and insurance firms pay a premium for quantitative rigor without requiring generative AI, and many gen AI postings are at tech companies where equity carries a larger share of total compensation than base salary.
Q. Which industries require AI skills from Data Scientists most often in 2026?
Energy leads with 93.3% of Data Scientist postings in that sector requiring AI, followed by retail (52.3%), finance (49.2%), technology (48.0%), and software (44.7%). Healthcare follows at 43.1%. Fintech posts the lowest rate among measured industries at 29.0%, likely reflecting a preference for interpretable classical models in regulated environments.
Q. What is the difference between building AI and using AI as a Data Scientist?
Job postings only capture AI skills employers explicitly list as requirements: engineers hired to design LLM pipelines, build RAG systems, or develop AI agents. They do not capture the ambient layer: GitHub Copilot, ChatGPT, and AI-assisted notebook workflows that most Data Scientists now use daily. Developer surveys from JetBrains (2026) find 90% of developers regularly use at least one AI tool at work. The 39.6% figure measures the depth of AI work required, not whether AI matters.
Q. Are junior or senior Data Scientists more likely to be hired for gen AI skills?
Junior-level Data Scientist postings have the highest new-wave AI adoption rate at 55.8%, meaning more than half of junior postings explicitly require generative AI skills. Senior postings sit at 39.0% and staff at 42.2%. The pattern suggests companies are rebuilding their junior Data Scientist pipeline with AI-native expectations, while many senior roles still center on traditional ML, statistical modeling, and deep expertise in a vertical.
Final Thoughts
The Data Scientist role in 2026 is not one job with an AI module bolted on. It is two overlapping jobs sharing a title: a traditional quantitative role that still runs the core of most business analytics and pays well for statistical depth, and a generative AI engineering role that is growing fast and increasingly defines what the junior pipeline looks like. Building across both layers, deep ML foundations plus practical gen AI application skills, positions you for the widest range of postings and the most resilient trajectory as the two tracks continue to converge.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.