The Score Is Decided Before You Draw a Single Component
You know Kafka. You know Spark. You know the medallion architecture. None of that saves you if you spend the first eight minutes jumping straight to tools.
In a mid-level Data Engineer interview on data pipeline architecture, 30 of 100 rubric points go purely to whether you addressed the interviewer's specific objectives. Another 30 go to whether your answer demonstrates the depth expected at this level. Together, that's 60% of your score settled in how you frame the problem, before you name a technology or sketch a data flow. The AI mock interview tracks this live, phase by phase. This walkthrough shows you where points go, and where they most often disappear.
Key Findings
- The rubric allocates 30 points each to Interviewer Objectives Alignment and Level-Specific Expectations, totaling 60% of the score before any code or diagram.
- Phase 1 (0-8 minutes) covers requirements framing: 4 checklist items must be hit before the design phase opens.
- Phase 2 (8-20 minutes) has 6 checklist items: ingestion pattern, layering, deduplication, late data, dual-SLA outputs, and schema management.
- Phase 3 (20-30 minutes) covers 5 operational items: retries, idempotent writes, monitoring, backfill, and downstream failure handling.
- Candidates who skip requirements framing and jump to tools typically miss all 4 Phase 1 checklist items, a deficit 22 minutes of strong technical answers cannot fully undo.
- The interview explicitly excludes deep distributed-systems theory: mid-level engineers are scored on practical judgment, not internals.
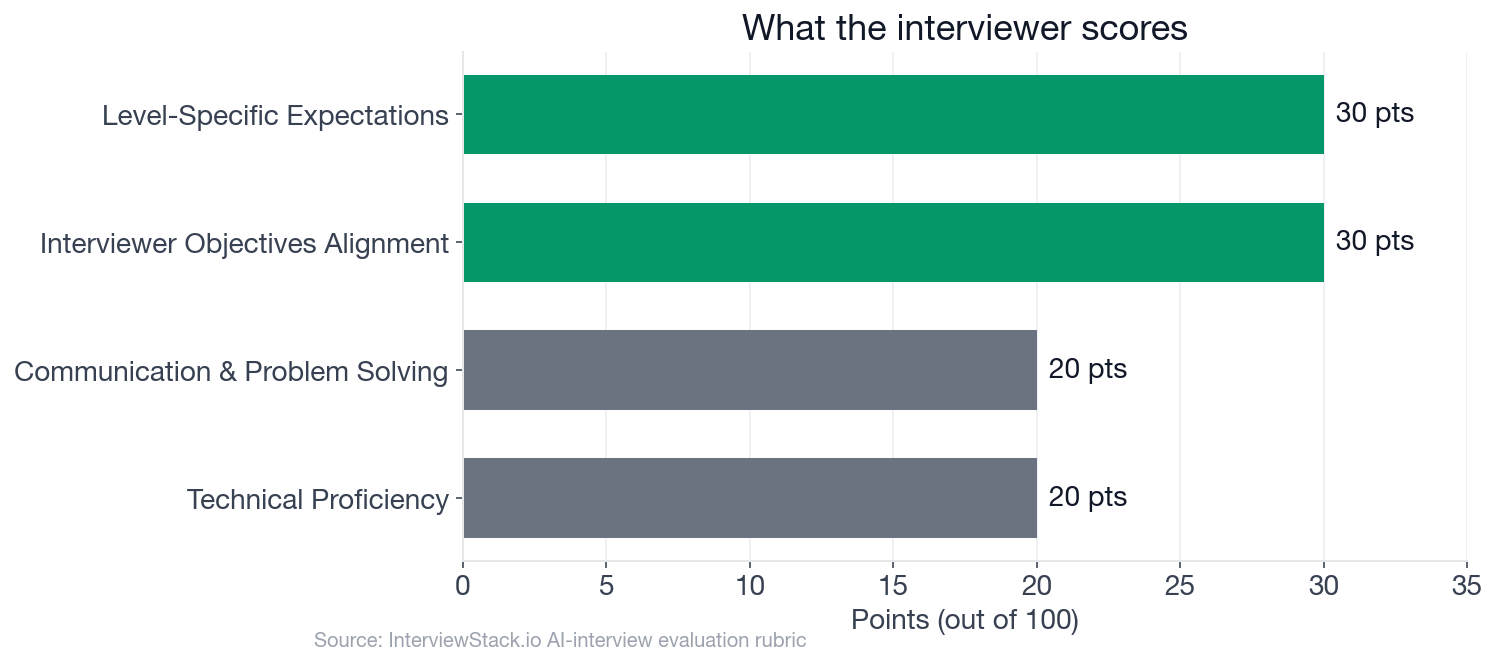
The four scoring dimensions and their weights. Technical accuracy accounts for only 20 of 100 points; how well you satisfy the interviewer's objectives and match the expected level together account for 60.
What the Data Engineer Data Pipeline Architecture Interview Tests
Here is the scenario the interviewer presents. What it is probing: your ability to turn an ambiguous analytics requirement into a concrete end-to-end architecture, gather the requirements that are missing, choose appropriate ingestion and processing patterns, and reason about freshness, correctness, and operational trade-offs at a mid-level scope.
The interview question
Your team supports analytics for a large consumer product with web and mobile clients. Product managers, data scientists, and finance analysts rely on trustworthy event data for dashboards, experimentation analysis, and daily business reporting.
Today, client applications emit user interaction events and backend services emit order and payment events. The current setup is unreliable: some events arrive late, schemas change without notice, and daily metrics occasionally differ between dashboards and finance reports.
Leadership wants a new pipeline that can support near-real-time product analytics while also producing reliable daily aggregates used by downstream teams.
Design an end-to-end data pipeline architecture for this platform, and walk me through how data would flow from producers to downstream consumers.
Notice the scenario withholds key constraints: event volume, acceptable lag, whether "near-real-time" means 5 minutes or 1 hour, who owns schema changes. A strong Phase 1 opens by surfacing those gaps before proposing anything. That's not being cautious; that's directly what the rubric rewards.
Walkthrough: Four Turns, Four Chances to Score or Slip
Turn 1: Streaming vs Batch Trade-offs
Interviewer: "How would you decide which parts of this pipeline should be streaming, micro-batch, or batch, and what trade-offs are you making?"
Turn 2: Late and Out-of-Order Events
Interviewer: "If mobile clients can be offline for hours and then send events late or out of order, how would your design handle that?"
Turn 3: Dual SLAs
Interviewer: "Suppose product analytics needs data within 5 minutes, but finance needs stable daily numbers with strong consistency. How would you support both use cases?"
Turn 4: Downstream Failure
Interviewer: "If a downstream warehouse load starts failing or lagging behind, how would you prevent data loss and operate the system safely?"
Why Reading This Is Not the Same as Surviving It Live
Every mistake above is obvious on the page. You can read this in 10 minutes and feel prepared.
The real test works differently: the interviewer asks these follow-ups in an order you don't control, at a pace that doesn't pause for reflection, and each question builds on your prior answer. A vague answer on Turn 1 puts you in a corner on Turn 3. The 30-minute clock creates real pressure that a blog post cannot simulate.
The only preparation that closes that gap is live reps under unscripted follow-up pressure. That is what the AI mock interview for Data Pipeline Architecture is built to give you.
The Complete 30-Minute Blueprint
This is the blueprint a strong candidate hits across all three phases. It is also exactly what the AI mock interview tracks you against in real time, with per-phase and per-dimension feedback after the session.
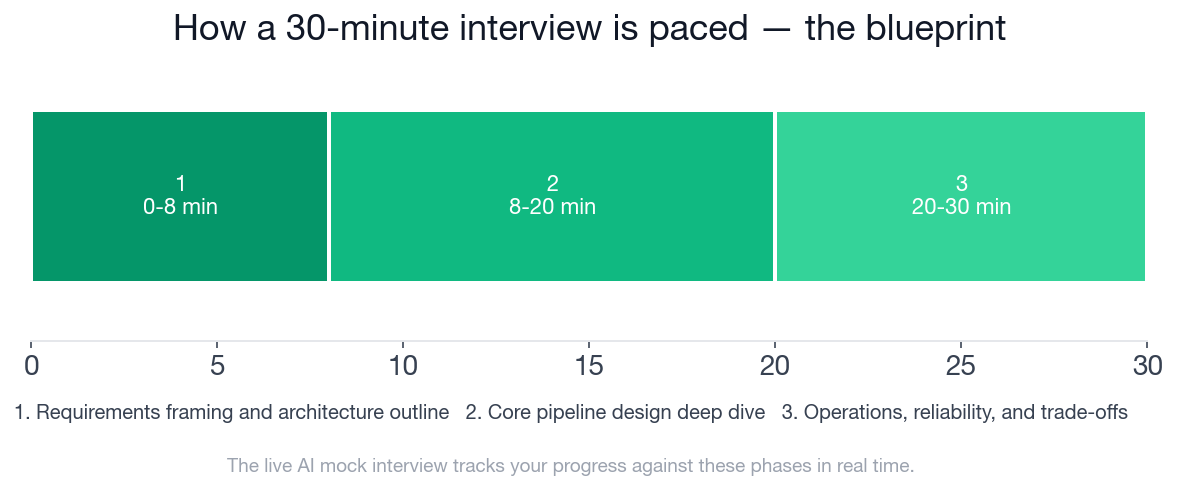
Three-phase structure of a 30-minute data pipeline architecture interview. The first 8 minutes are entirely requirements framing. The rubric scores you on all three phases.
- ✓Asks about primary consumers such as dashboards, experimentation, and finance reporting.
- ✓Asks about freshness expectations, correctness needs, scale, and expected event patterns.
- ✓Separates raw event capture from curated analytics outputs.
- ✓Presents a clear end-to-end flow rather than isolated tools.
- ✓Chooses and justifies ingestion pattern such as event bus plus batch backfill or micro-batch processing.
- ✓Describes raw/bronze and curated/silver-gold style layers or an equivalent staging-to-modeled approach.
- ✓Explains how events are keyed, partitioned, and deduplicated.
- ✓Addresses late or out-of-order data with watermarking, reprocessing windows, or correction jobs.
- ✓Differentiates outputs for near-real-time analytics versus stable daily aggregates.
- ✓Mentions schema registry, versioning, validation, or contract checks for producer changes.
- ✓Discusses retries, idempotent writes, checkpointing, and failure recovery in a concrete way.
- ✓Includes monitoring for lag, throughput, freshness, data quality, and load failures.
- ✓Describes backfill or replay strategy without corrupting downstream tables.
- ✓Explains how to handle downstream warehouse outages or backpressure safely.
- ✓Makes reasonable technology choices and acknowledges cost and complexity trade-offs.
Practice the Live Round
The AI mock interview for Data Engineer: Data Pipeline Architecture runs this exact question with scored follow-ups, tracks you against all three phases, and delivers feedback on all four rubric dimensions after the session. That feedback tells you which phase you're losing points in, not just whether your answer "felt right."
If you want targeted drilling before the full round, the Data Pipeline Architecture question bank covers ingestion patterns, schema evolution, late data handling, and operational reliability topic by topic. For a full picture of what skills companies require and pay for, the Data Engineer skills analysis covers 6,877 active postings including the pipeline and orchestration skills that show up most in onsite rounds. You can also browse current Data Engineer openings on the job board to see how these topics appear in real job descriptions.
FAQ
Q. How is a data pipeline architecture interview scored at a leading tech company?
The rubric allocates 100 points across four dimensions: Interviewer Objectives Alignment (30 points), Level-Specific Expectations (30 points), Technical Proficiency (20 points), and Communication and Problem Solving (20 points). Objectives Alignment and Level Expectations together account for 60% of your score.
Q. What should you cover in the first 8 minutes of a data pipeline design interview?
The blueprint's requirements-framing phase runs from 0 to 8 minutes. A strong candidate asks about primary consumers (dashboards, experimentation, finance), clarifies freshness SLAs and correctness needs, separates raw event capture from curated analytics outputs, and sketches a clear end-to-end flow before naming a single tool.
Q. How do you handle late and out-of-order events in a data pipeline interview?
The expected answer covers watermarking or reprocessing windows for late arrivals, idempotent writes so reprocessing does not duplicate records, and a correction or backfill job for events that arrive after the daily aggregate has already run. Skipping this in the Core Pipeline Design phase risks losing points under Level-Specific Expectations.
Q. How do you support both near-real-time analytics and stable daily aggregates in the same pipeline?
A strong answer separates the serving layers: a streaming or micro-batch branch (5-minute latency) feeding a hot analytics table, and a separately scheduled batch job producing stable daily aggregates with full-event-set correctness. Finance and product analytics should not share the same materialization path.
Q. What does the AI mock interview check in a data pipeline architecture round?
The AI mock interview tracks you against the three-phase blueprint in real time: requirements framing and architecture outline (0 to 8 minutes), core pipeline design deep dive (8 to 20 minutes), and operations, reliability, and trade-offs (20 to 30 minutes). Feedback is generated on all four rubric dimensions after the session.
Q. What level is this data pipeline architecture blueprint designed for?
This blueprint is calibrated for mid-level data engineers (2-5 years of experience). At this level, the interviewer expects a solid, maintainable design for a common analytics platform with moderate guidance, correct identification of concerns like deduplication and late data, and at least two reasonable architectural options compared on trade-offs.
One Practice Round Changes Everything
Reading the blueprint takes 10 minutes. Knowing the framework under pressure, across four unscripted follow-ups with a timer running, takes practice. Run the live round, see where the rubric scores you, and find out which phase you are actually losing points in. The Data Engineer mock interview is where that feedback lives.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.